Updated 4/15/2024
NOTE: Due to RedHat’s decision to stop maintaining the upstream Gluster project, the TrueNAS SCALE gluster functionality has been deprecated. The gluster clustering feature is disabled in TrueCommand 3.0 and later. Further, TrueNAS SCALE 24.04 has removed the deprecated gluster backend. Systems installed with SCALE 24.04 (Dragonfish) or newer will be unable to use the deprecated gluster clustering feature. Other clustering features such as Minio and Syncthing are unimpacted.
TrueNAS SCALE was released on “Twosday” 2/22/22. Since this time, tens of thousands of users adopted it as a single node hyperconverged system with unified storage, containers, and VMs. In parallel, development and testing of scale capabilities has progressed well, and the Release of SCALE 22.12 (Bluefin) significantly improves the clustering and scale options. In this blog we share a technical overview of how TrueNAS SCALE Bluefin uses clustering technologies and what the user benefits are.
What is clustering?
Every compute or storage system is based on processors, memory, and some amount of storage, typically in a single enclosure with its own power supplies and fans. It’s possible to scale-up these systems by using larger processors and more RAM. The storage capacity can also scale-up by adding drives and even expansion shelves (JBODs). However, there is a scalability limit that is eventually reached. Beyond that limit, scale technologies are used to break these barriers.  The feasible limit for scale-up storage based on today’s hardware technology is up to about 64 cores, 1 TB RAM and up to 1200 drives of 18 TB each. That is over 20 petabytes (PB) of raw storage! A two-node cluster of controllers can be used to deliver High Availability (HA). While 20 PB is a huge amount of data for individuals or small businesses, there are many large organizations that have to manage hundreds of PBs to even Exabytes of data. Scale storage allows growth from 20 PB to an Exabyte by combining many systems (nodes) into a cluster. A cluster can have a hundred nodes across which an architect can deploy additional CPU cores, RAM, drive counts, network bandwidth, and storage capacity. From the user or the client perspective, the cluster appears as a single, larger, and more scalable system. The scale cluster can also be more reliable than a single system. A node can be taken down or removed from the cluster without interrupting client storage operations. This increases service and application availability, which can be very important, allowing TrueNAS SCALE to enable extreme Availability as it matures. Clusters are techniques for enabling massive capacity, bandwidth, and availability by aggregating systems or nodes. It should be noted that clusters do not decrease latency or individual client performance. They consume additional resources to coordinate data between the nodes, proving that there is no such thing as a free lunch.
The feasible limit for scale-up storage based on today’s hardware technology is up to about 64 cores, 1 TB RAM and up to 1200 drives of 18 TB each. That is over 20 petabytes (PB) of raw storage! A two-node cluster of controllers can be used to deliver High Availability (HA). While 20 PB is a huge amount of data for individuals or small businesses, there are many large organizations that have to manage hundreds of PBs to even Exabytes of data. Scale storage allows growth from 20 PB to an Exabyte by combining many systems (nodes) into a cluster. A cluster can have a hundred nodes across which an architect can deploy additional CPU cores, RAM, drive counts, network bandwidth, and storage capacity. From the user or the client perspective, the cluster appears as a single, larger, and more scalable system. The scale cluster can also be more reliable than a single system. A node can be taken down or removed from the cluster without interrupting client storage operations. This increases service and application availability, which can be very important, allowing TrueNAS SCALE to enable extreme Availability as it matures. Clusters are techniques for enabling massive capacity, bandwidth, and availability by aggregating systems or nodes. It should be noted that clusters do not decrease latency or individual client performance. They consume additional resources to coordinate data between the nodes, proving that there is no such thing as a free lunch.
What are the types of TrueNAS SCALE clustering?
There are several types of clustering. Each type of clustering has a mixture of different benefits and tradeoffs. The best deployment configuration will always depend on the specific requirements. TrueNAS SCALE is unique in that it offers choice among several types of clustering and also allows users to start using it as a single, discrete node. By contrast, most clustered storage solutions have limited clustering options. Based on erasure coding, a minimum of three nodes are required to get started. 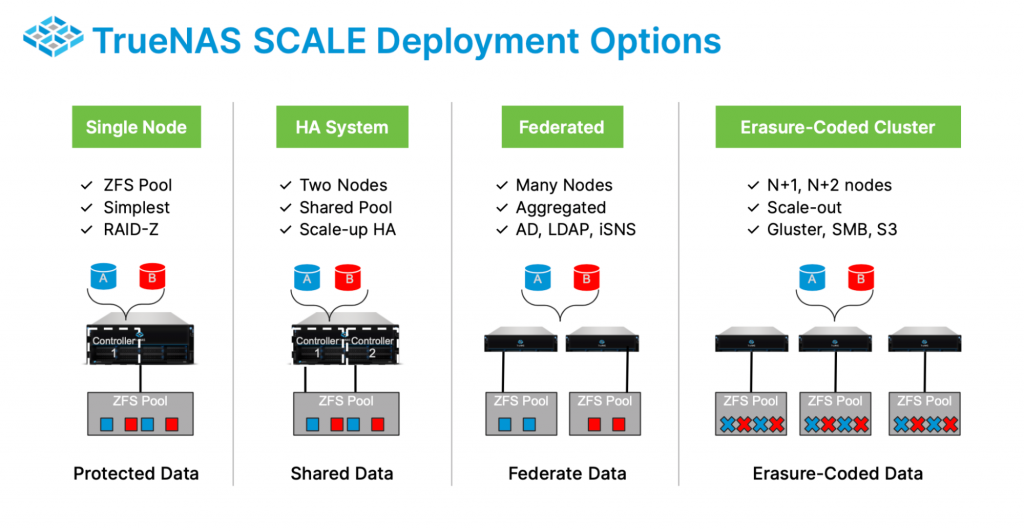
Shared Storage Clusters
One type of clustering known as shared storage clusters are built such that all nodes have access to the same storage pool. If one node fails, the other nodes have access to the storage and can carry on. These are well suited for modest size systems with more processing needs (e.g., databases) or high availability (HA) requirements. As compared to shared-nothing clusters, the capacity of the shared storage pool is smaller. TrueNAS SCALE uses a shared storage model to support HA systems. Two nodes are used to manage a shared ZFS pool. If one node fails, the other node can take over the responsibilities. This improves the reliability of a system from 99.9% to 99.999%. The primary benefit of shared storage is that data does not have to be replicated between nodes. The data is efficiently supported in a standard ZFS pool. This reduces the cost of reliable storage by as much as 50% while also providing the best single client latency and bandwidth for storage consumers. The capacity and reliability limit for this clustered layout for TrueNAS is a little over 20 PB. Shared storage HA requires significant platform customization to make it reliable and is only available as TrueNAS Appliances. TrueNAS SCALE can be used on the TrueNAS M-Series platform and deliver HA for both storage services and for its VMs and container workloads.
Shared-nothing Clusters
Shared-nothing Clusters is the term used for clusters where the storage is dedicated to each node. The advantage of this architecture is that it can scale to much larger systems. These are the techniques used by Google, Facebook, and Apple to handle their massive datasets. There are several types of scale or shared nothing clusters: Federated clusters use some form of common directory service to aggregate systems. Each system is responsible for its own data. Lightweight Directory Access Protocol (LDAP) is used for NFS. iSNS is used for iSCSI. SMB storage can be coordinated with Active Directory (AD). Federation solves some administration problems, but does not scale smoothly with each dataset typically constrained to a single system. This would more commonly be used by downstream Applications with their own forms of redundancy and load balancing between the federated nodes. Scale Clusters are typically based on Erasure Coding. Datasets can span many nodes, and clusters can grow linearly. Erasure-coded clusters take each piece of data and code it in N chunks. The coding is such that one or more chunks can be lost and the data can still be restored. Erasure-coding is very robust and efficient. Instead of replicating all data, only 20-50% additional data is usually required. This type of clustering will enable maximum storage capacity, availability and redundancy, but at the cost of individual client bandwidth and latency. TrueNAS SCALE supports erasure-coding with both glusterfs “dispersed-mode” and with Minio erasure coding for S3 compatible object storage.
TrueNAS SCALE supports many types of Clustering
As described above, TrueNAS SCALE supports many types of clustering approaches. The best clustering approach depends on the specific protocols and the use-case requirements. The following table attempts to summarize the clustering modes available for the different protocols. 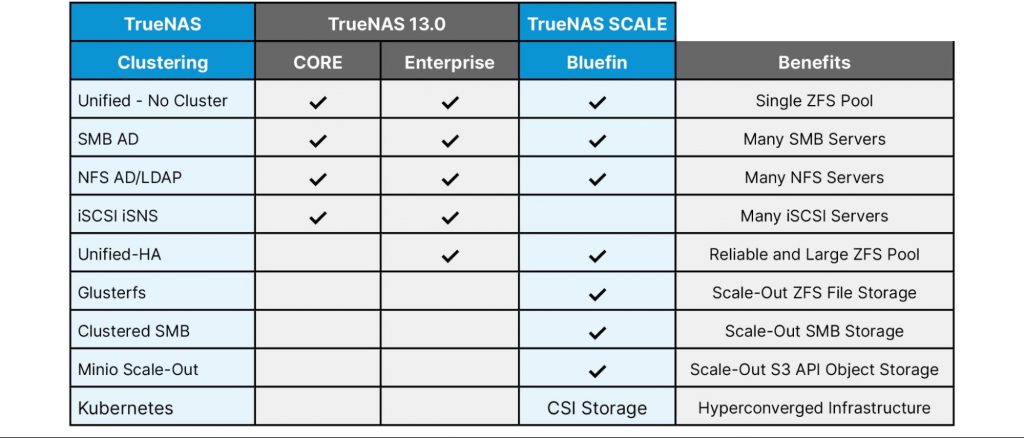
Clustering Efficiency and Performance
Calculating the impact of clustering on capacity and performance can become more complex than expected. As you add nodes and drives, capacity and performance increases, while at the same time, the efficiency of those nodes decreases. Clustering protocols require CPU and networking resources to manage the cluster. The following chart provides rough estimates on the efficiency of the nodes and their drives for different clustering models. HA systems are very efficient and should be used if the workload is not too large. Erasure-coded clusters grow capacity more quickly than performance. It’s very much like ZFS pools with RAID-Z vdevs. 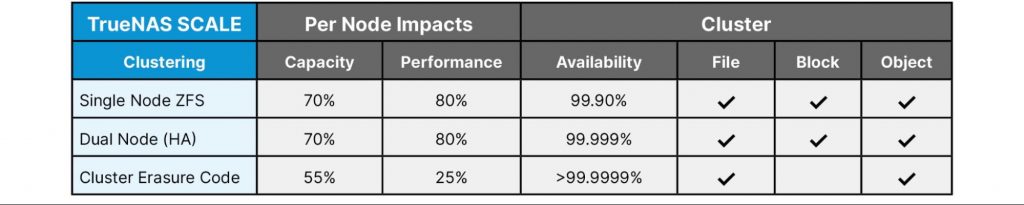
Clustering Features
ZFS has many data optimization and protection features that are used on scale-up systems. TrueNAS SCALE supports all of those existing scale-up features. Some of those features are redone when scale clusters are used: Online Growth is provided via the addition of groups of nodes. The size of the group is generally 2 for a mirror layout or the size of the erasure code (3-10). It is simpler to manage if nodes are similar in size and performance. TrueNAS SCALE has the fundamental APIs to enable this, and there is ongoing work to build simpler tools in TrueCommand. Node replacement is provided via TrueCommand 2.3 and 22.12 Bluefin.. If a node is failing or otherwise needs to be replaced, a simple process can be followed to replace the faulted node. Data is then automatically healed as required until the cluster is back to normal operating state.
The Evolution of TrueNAS SCALE
TrueNAS SCALE Angelfish was the first version of TrueNAS SCALE, and as of the update of this blog in December 2022 over 30,000 TrueNAS Community users have participated and tested on their widely varying hardware platforms and VMs. This Angelfish version introduced gluster for scale ZFS file services and clustered Minio for scale S3 service.  TrueNAS SCALE Bluefin is the current version. It reached RELEASE on December 13, 2022. Bluefin includes improved clustering with simpler node replacements. TrueNAS SCALE Cobia will be the next version. It will have many enhancements and is expected to be released later in 2023. We welcome developers and testers to continue to participate in this process. Increasing the quality and reliability of each release is a primary goal. Please contact iX if you are looking for more information on how to develop, test, or use TrueNAS SCALE.
TrueNAS SCALE Bluefin is the current version. It reached RELEASE on December 13, 2022. Bluefin includes improved clustering with simpler node replacements. TrueNAS SCALE Cobia will be the next version. It will have many enhancements and is expected to be released later in 2023. We welcome developers and testers to continue to participate in this process. Increasing the quality and reliability of each release is a primary goal. Please contact iX if you are looking for more information on how to develop, test, or use TrueNAS SCALE.