I have a DIY TrueNAS scale system that I set up 5-6 months ago, about once a month one of my SSD's will start to error and fault with read/write errors, for a while I can just reboot to clear it, but after a few weeks the drive eventually faults for good and never comes back If it remove it and connect it to another system it doesn't show up at all.
I've replaced 4 drives so far, about one a month, and I started to think I had one bad power/HBA cable until I started seeing faults now on 2 seperate drives. Due to life events I just RMA'd a couple drives thinking it was a bad batch, then started just buying new ones to keep it chugging along. The SSD's I started with I couldn't get anymore, so now I have a mix of vendors and they're starting to fault now too. I'd like to figure out what is going on as I have 2 faulted drives and only 1 spare to extend its life a bit. Thankfully I have a remote spinning rust server to backup my mission critical data [read: family photos] but I'd rather not lose all my other data..
I'm not looking for a miracle, but I'd love to figure out what is causing this so I can replace just that (hopefully) one part, since I don't have many spare parts, just a couple 2TB ssds that I planned to keep everything running for a bit. Please let me know any info I can provide to help narrow down the issue
System specs:

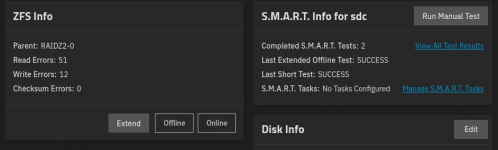
The latest ssd to fault:

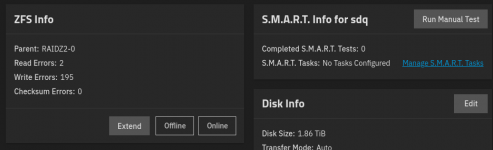
SSD that has been faulted for a bit while I waited for a new SSD to arrive:

I've replaced 4 drives so far, about one a month, and I started to think I had one bad power/HBA cable until I started seeing faults now on 2 seperate drives. Due to life events I just RMA'd a couple drives thinking it was a bad batch, then started just buying new ones to keep it chugging along. The SSD's I started with I couldn't get anymore, so now I have a mix of vendors and they're starting to fault now too. I'd like to figure out what is going on as I have 2 faulted drives and only 1 spare to extend its life a bit. Thankfully I have a remote spinning rust server to backup my mission critical data [read: family photos] but I'd rather not lose all my other data..
I'm not looking for a miracle, but I'd love to figure out what is causing this so I can replace just that (hopefully) one part, since I don't have many spare parts, just a couple 2TB ssds that I planned to keep everything running for a bit. Please let me know any info I can provide to help narrow down the issue
System specs:
- TrueNAS-SCALE-22.12.3.2
- LSI SAS 9300-16I
- 16 x 2TB SDDs for storage connected to 9300-16I:
- 10 x PNY CS900 2TB
- 6 x TEAMGROUP T-Force Vulcan Z 2TB
- 2 x 240GB HPE in boot pool connected to motherboard sata
- ASRock Rack E3C246D4U Motherboard
- Intel core i3-9100T
- 16GB DDR4-2400MHz ECC NEMIX memory
- Not sure on the PSU, think it was a plain Corsair 600 or 700W ATX PSU
The latest ssd to fault:
SSD that has been faulted for a bit while I waited for a new SSD to arrive: