
ZFS does two different things very well. One is storage of large sequentially-written files, such as archives, logs, or data files, where the file does not have the middle bits modified after creation. This is optimal for RAIDZ. It's what most people come to ZFS for, and what a vast majority of the information out there is about. The other is storage of small, randomly written and randomly read data. This includes such things as database storage, virtual machine disk (ESXi VMDK, etc) storage, and other uses where lots of updates are made within the data. This is optimal for mirrors. The remainder of this document is generally aimed at VM storage and iSCSI, but is still valid for database storage, NFS datastores, etc.
1) Recognize the biggest underlying fact: ZFS is a copy-on-write filesystem.
With a bare hard disk, if you issue a write command to LBA 5678, that specific LBA on the HDD is written, and will be right after LBA 5677 and right before LBA 5679. However, with ZFS, when you write to a virtual disk's LBA 5678, ZFS allocates a new location for that new block, writes it, and frees the old. This means that your system which might have previously had LBA's 5677, 5678, 5679 as sequential data on the ZFS pool will now have 5678 in a different spot. If you try to do a read of the "sequential" LBA's 5677, 5678, 5679 from the VM, there will be a seek in the middle. This is generally referred to as fragmentation. This property would seem to suck, but it brings with it the ability to do a variety of cool things, including snapshots.
You need to pay particular attention to fragmentation as a design issue.
2) You need to use mirrors for performance.
ZFS generally does not do well with block storage on RAIDZ. RAIDZ is optimized towards variable length ZFS blocks. Unlike "normal" RAID, RAIDZ computes parity and stores it with the ZFS block, and on a RAIDZ3 where you store a single 4K sector, you get three parity sectors stored with it (4x space amplification)! While there are optimizations you can do to make it suck less, the fact is that a RAIDZ vdev tends to adopt the IOPS characteristics of the slowest component member. This is partly because of what Avi calls "seek binding", because multiple disks have to participate in a single operation because the data is spread across the disks. Your ten drive RAIDZ2 vdev may end up about as fast as a single drive, which is fine for archival storage, but not good for storing lots of active VM's on.
By way of comparison, a two-way mirror vdev can be servicing two different operations (clients reading) simultaneously, a three-way mirror vdev can even be servicing three different operations. There is massive parallelism available with mirrors.
Additional reading:
Some differences between RAIDZ and mirrors, and why we use mirrors for block storage
3) Plan to use lots of vdevs.
For most VM or database applications, you have lots of things wanting to do lots of I/O. While hard disks are much larger than they were 25 years ago (16TB vs 1GB), their ability to sustain random I/O is virtually the same (approximately 100-200 random IOPS). With the advent of virtualization, hard drive IOPS are getting shared between VM's, creating an effective reduction in HDD IOPS per VM over what you'd get from a physical workload. ZFS can help with the read workload through ARC and L2ARC caching, but for writes, it always goes to the pool. Using more vdevs increases the available pool IOPS.
Most virtualization designs set a target level of IOPS per VM. It helps to recognize that a single HDD vdev only has maybe 200-300 mixed IOPS available, so if you are planning on 50 IOPS for each VM, and you want 40 VM's, you need probably at least 8 vdevs to be in the ballpark, 10 would be better.
4) ZFS write speeds are closely coupled to easily finding large contiguous ranges of free space.
ZFS writes are a complex topic. One of the biggest factors in ZFS write speeds is the ability of the system to find large contiguous runs of free space. This ties in to fragmentation as well. In general, ZFS will tend to write a transaction group to disk as a large sequential write if it can find the free space to do so. It doesn't matter if the files being written are for sequential or random data! Because of this, ZFS seems to be amazingly fast at writes especially on a relatively empty pool. You can write a large sequential file to the pool and it goes fast. You can rewrite random data blocks and it also goes fast -- MUCH faster than if it were seeking around!
But there's a dark side to this. If you are writing on a fullish fragmented pool, all writes will be slow. You can be writing what you think is a large sequential file, and ZFS will be having to scrounge together little bits of space here and there due to fragmentation, and it will be slow.
Prior analysis of this suggests that this effect becomes very significant at around 50%. This isn't to say that every pool that is 50% will be very slow, but that over time, a pool with 50% occupancy will tend to stabilize at a steady state with relatively poor write performance in the long run.
5) Because of this, a 12TB 5400RPM drive is a lot more valuable to most pools than a 6TB 7200RPM drive.
By the time you are seeking heavily enough for you to be concerned about the RPM of the drive, you have already dropped from being able to write at 150-200MBytes/sec (sequential) to the drive down to just a few MBytes/sec (random). A 7200RPM drive going at even 10MBytes/sec (200 48KByte random writes per second) is nowhere near as fast as a 5400RPM drive writing sequentially.
Buy 5400/5900RPM drives much larger than you'd otherwise think you need if you want fast write speeds. I think 7200RPM drives are for chumps.
6) Keep the pool occupancy rate low.
This ties in with the write speed strategy. ZFS needs to be able to easily find large amounts of contiguous free space. Our friends at Delphix did an analysis of steady state performance of ZFS write speeds vs pool occupancy on a single-drive pool and came up with this graph:
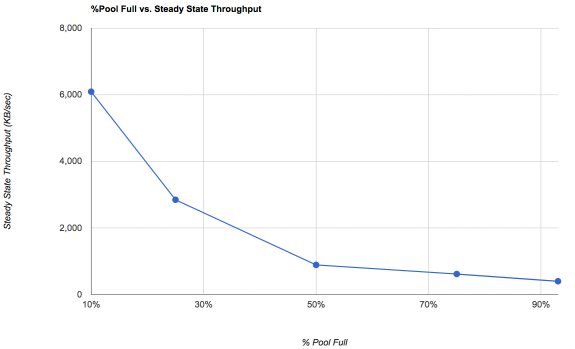
A 10%-full pool is going to fly for writes. By the time you get up to 50%, the steady state performance is already pretty bad. Not everyone is going to get there... if you have a lot of content that is never rewritten, your fragmentation rates may be much better because you haven't rewritten as much stuff.
Particularly noteworthy: The pool at 10% full is around 6x faster than the pool at 50%.
But what about reads? We've spent all this time talking about writes and free space. ZFS rewards you with better write speeds if you give it gobs of free space. Reads still suffer from fragmentation and seeks!
This is true. ZFS really only has one mechanism to cope with read fragmentation: the ARC (and L2ARC). So these next bits are somewhat simpler.
7) Ideally you want to cache the working set
The working set is a term used to describe "active data" on the pool -- data that is being accessed. For example, on most UNIX systems, the disk blocks for /bin/sh are frequently read, but the disk blocks for the manual page for phttpget(8) are probably not ever accessed. It would be valuable to have the disk blocks for /bin/sh in ARC but not phttpget's man page in ARC. How exactly you wish to define the working set is a good question. Blocks read within a 5 minute period? 60 minute? Once a day? This doesn't have a "correct" answer, but it isn't unusual for the working set of a VM to be in the range of 1/50th to 1/20th of the on-disk size of the VM.
By caching the working set, you free the pool to focus on reading the occasional thing not in the working set, and to focus on writes. A ZFS system with the entire working set cached will show almost no pool read activity.
A lot of the working set isn't frequently accessed. It's fine for that to be covered by L2ARC. You want to size your ARC to cover the frequently accessed stuff plus enough space for the L2ARC indirect pointers.
Additional reading: Why iSCSI often requires more resources for the same result
8) It is best to have at a bare minimum 64GB ARC to do block storage.
Especially with iSCSI, block storage tends to do poorly on ZFS unless there is a lot of cache. While there is no one-size-fits-all rule, doing anything more than trite VM storage seems to go poorly with less than 64GB ARC. 64GB of RAM is probably suitable on CORE, which has better memory management. For SCALE, which by default only uses half its RAM for ARC, 128GB RAM is probably the recommended floor. Generally, it may be necessary to provide 512GB ARC or more, depending on the size of the working set, the iSCSI volume size, and other factors.
9) VM storage is an exercise in parallelism and fragmentation
Don't bother doing conventional benchmarks for your VM storage pool. A good VM storage pool is designed to be doing many operations in parallel, a thing that many benchmarks suck at. It is far better to run benchmarks designed for heavy parallelism from multiple VM's in your production setup, and don't just run them once when the pool is empty, but rather let it get fragmented and then see how it is.
10) Don't misunderstand the ZIL.
The ZFS Intent Log is not a write cache. We call a Separate LOG device the "SLOG" for a reason. It isn't a cache.
No amount of SLOG will make up for a crappy RAIDZ pool design. (Again! ZIL/SLOG Is Not A Cache!)
The fastest sustained write speed your pool will EVER be capable of is when you turn off sync writes. That's it. No more.
Adding sync writes (whether ZIL or SLOG) will ALWAYS slow down your pool compared to the non-sync write speed.
We use sync writes on VM data to ensure that a VM remains consistent if the filer panics or loses power. If this is not a concern for you, feel free to disable sync VM writes, and things will go faster!
Additional reading: Some insights into SLOG/ZIL with ZFS on FreeNAS
11) Write speeds greater than read speeds?
When ZFS is "writing" to the pool, it is actually creating a transaction group in RAM to commit to disk later. If ZFS is "reading" from the pool and the data is not in ARC/L2ARC, it actually needs to go out to a HDD to pull the data in. If your read speeds are slower than your write speeds, it just means that the data being read wasn't in cache. If you expected that data to be in the working set, perhaps your working set is too small.
12) Make sure your drives aren't SMR.
Shingled magnetic recording drives are generally unsuitable for FreeNAS and ZFS, but are particularly horrible for block storage due to the need to be rewriting small blocks in the middle of random tracks. If you use SMR for block storage, expect it to suck. Sorry. No gentle way to say it.
13) Use an appropriate network.
Bear in mind that if you are using 1Gbps ethernet, you are not going to see a lot of speed to your disk subsystem. Even if you do two of them, this only works out to 250MBytes/sec, about the speed of a single SATA HDD. It is usually advisable to be using a network that is at least 10Gbps with high quality network cards. Initiators often offer the ability to do round robin, but for this to work correctly, you need to have a properly designed network. This means two or more separate networks.
Additional reading: Multiple network interfaces on a single subnet
14) Don't ignore timeouts.
iSCSI initiators expect a snappy response from the iSCSI target. A connection that goes idle for five seconds is typically reset by the protocol. A poorly implemented iSCSI storage system using ZFS can exceed that in a number of ways. If you don't have sufficient CPU, if you don't have sufficient memory, if you don't have a fast enough network, if you have too many VM's competing for resources, if you have too much fragmentation, all of these things can cause iSCSI timeouts. These are a warning that you're under-resourced and in a position where you might eventually fail.
1) Recognize the biggest underlying fact: ZFS is a copy-on-write filesystem.
With a bare hard disk, if you issue a write command to LBA 5678, that specific LBA on the HDD is written, and will be right after LBA 5677 and right before LBA 5679. However, with ZFS, when you write to a virtual disk's LBA 5678, ZFS allocates a new location for that new block, writes it, and frees the old. This means that your system which might have previously had LBA's 5677, 5678, 5679 as sequential data on the ZFS pool will now have 5678 in a different spot. If you try to do a read of the "sequential" LBA's 5677, 5678, 5679 from the VM, there will be a seek in the middle. This is generally referred to as fragmentation. This property would seem to suck, but it brings with it the ability to do a variety of cool things, including snapshots.
You need to pay particular attention to fragmentation as a design issue.
2) You need to use mirrors for performance.
ZFS generally does not do well with block storage on RAIDZ. RAIDZ is optimized towards variable length ZFS blocks. Unlike "normal" RAID, RAIDZ computes parity and stores it with the ZFS block, and on a RAIDZ3 where you store a single 4K sector, you get three parity sectors stored with it (4x space amplification)! While there are optimizations you can do to make it suck less, the fact is that a RAIDZ vdev tends to adopt the IOPS characteristics of the slowest component member. This is partly because of what Avi calls "seek binding", because multiple disks have to participate in a single operation because the data is spread across the disks. Your ten drive RAIDZ2 vdev may end up about as fast as a single drive, which is fine for archival storage, but not good for storing lots of active VM's on.
By way of comparison, a two-way mirror vdev can be servicing two different operations (clients reading) simultaneously, a three-way mirror vdev can even be servicing three different operations. There is massive parallelism available with mirrors.
Additional reading:
Some differences between RAIDZ and mirrors, and why we use mirrors for block storage
3) Plan to use lots of vdevs.
For most VM or database applications, you have lots of things wanting to do lots of I/O. While hard disks are much larger than they were 25 years ago (16TB vs 1GB), their ability to sustain random I/O is virtually the same (approximately 100-200 random IOPS). With the advent of virtualization, hard drive IOPS are getting shared between VM's, creating an effective reduction in HDD IOPS per VM over what you'd get from a physical workload. ZFS can help with the read workload through ARC and L2ARC caching, but for writes, it always goes to the pool. Using more vdevs increases the available pool IOPS.
Most virtualization designs set a target level of IOPS per VM. It helps to recognize that a single HDD vdev only has maybe 200-300 mixed IOPS available, so if you are planning on 50 IOPS for each VM, and you want 40 VM's, you need probably at least 8 vdevs to be in the ballpark, 10 would be better.
4) ZFS write speeds are closely coupled to easily finding large contiguous ranges of free space.
ZFS writes are a complex topic. One of the biggest factors in ZFS write speeds is the ability of the system to find large contiguous runs of free space. This ties in to fragmentation as well. In general, ZFS will tend to write a transaction group to disk as a large sequential write if it can find the free space to do so. It doesn't matter if the files being written are for sequential or random data! Because of this, ZFS seems to be amazingly fast at writes especially on a relatively empty pool. You can write a large sequential file to the pool and it goes fast. You can rewrite random data blocks and it also goes fast -- MUCH faster than if it were seeking around!
But there's a dark side to this. If you are writing on a fullish fragmented pool, all writes will be slow. You can be writing what you think is a large sequential file, and ZFS will be having to scrounge together little bits of space here and there due to fragmentation, and it will be slow.
Prior analysis of this suggests that this effect becomes very significant at around 50%. This isn't to say that every pool that is 50% will be very slow, but that over time, a pool with 50% occupancy will tend to stabilize at a steady state with relatively poor write performance in the long run.
5) Because of this, a 12TB 5400RPM drive is a lot more valuable to most pools than a 6TB 7200RPM drive.
By the time you are seeking heavily enough for you to be concerned about the RPM of the drive, you have already dropped from being able to write at 150-200MBytes/sec (sequential) to the drive down to just a few MBytes/sec (random). A 7200RPM drive going at even 10MBytes/sec (200 48KByte random writes per second) is nowhere near as fast as a 5400RPM drive writing sequentially.
Buy 5400/5900RPM drives much larger than you'd otherwise think you need if you want fast write speeds. I think 7200RPM drives are for chumps.
6) Keep the pool occupancy rate low.
This ties in with the write speed strategy. ZFS needs to be able to easily find large amounts of contiguous free space. Our friends at Delphix did an analysis of steady state performance of ZFS write speeds vs pool occupancy on a single-drive pool and came up with this graph:
A 10%-full pool is going to fly for writes. By the time you get up to 50%, the steady state performance is already pretty bad. Not everyone is going to get there... if you have a lot of content that is never rewritten, your fragmentation rates may be much better because you haven't rewritten as much stuff.
Particularly noteworthy: The pool at 10% full is around 6x faster than the pool at 50%.
But what about reads? We've spent all this time talking about writes and free space. ZFS rewards you with better write speeds if you give it gobs of free space. Reads still suffer from fragmentation and seeks!
This is true. ZFS really only has one mechanism to cope with read fragmentation: the ARC (and L2ARC). So these next bits are somewhat simpler.
7) Ideally you want to cache the working set
The working set is a term used to describe "active data" on the pool -- data that is being accessed. For example, on most UNIX systems, the disk blocks for /bin/sh are frequently read, but the disk blocks for the manual page for phttpget(8) are probably not ever accessed. It would be valuable to have the disk blocks for /bin/sh in ARC but not phttpget's man page in ARC. How exactly you wish to define the working set is a good question. Blocks read within a 5 minute period? 60 minute? Once a day? This doesn't have a "correct" answer, but it isn't unusual for the working set of a VM to be in the range of 1/50th to 1/20th of the on-disk size of the VM.
By caching the working set, you free the pool to focus on reading the occasional thing not in the working set, and to focus on writes. A ZFS system with the entire working set cached will show almost no pool read activity.
A lot of the working set isn't frequently accessed. It's fine for that to be covered by L2ARC. You want to size your ARC to cover the frequently accessed stuff plus enough space for the L2ARC indirect pointers.
Additional reading: Why iSCSI often requires more resources for the same result
8) It is best to have at a bare minimum 64GB ARC to do block storage.
Especially with iSCSI, block storage tends to do poorly on ZFS unless there is a lot of cache. While there is no one-size-fits-all rule, doing anything more than trite VM storage seems to go poorly with less than 64GB ARC. 64GB of RAM is probably suitable on CORE, which has better memory management. For SCALE, which by default only uses half its RAM for ARC, 128GB RAM is probably the recommended floor. Generally, it may be necessary to provide 512GB ARC or more, depending on the size of the working set, the iSCSI volume size, and other factors.
9) VM storage is an exercise in parallelism and fragmentation
Don't bother doing conventional benchmarks for your VM storage pool. A good VM storage pool is designed to be doing many operations in parallel, a thing that many benchmarks suck at. It is far better to run benchmarks designed for heavy parallelism from multiple VM's in your production setup, and don't just run them once when the pool is empty, but rather let it get fragmented and then see how it is.
10) Don't misunderstand the ZIL.
The ZFS Intent Log is not a write cache. We call a Separate LOG device the "SLOG" for a reason. It isn't a cache.
No amount of SLOG will make up for a crappy RAIDZ pool design. (Again! ZIL/SLOG Is Not A Cache!)
The fastest sustained write speed your pool will EVER be capable of is when you turn off sync writes. That's it. No more.
Adding sync writes (whether ZIL or SLOG) will ALWAYS slow down your pool compared to the non-sync write speed.
We use sync writes on VM data to ensure that a VM remains consistent if the filer panics or loses power. If this is not a concern for you, feel free to disable sync VM writes, and things will go faster!
Additional reading: Some insights into SLOG/ZIL with ZFS on FreeNAS
11) Write speeds greater than read speeds?
When ZFS is "writing" to the pool, it is actually creating a transaction group in RAM to commit to disk later. If ZFS is "reading" from the pool and the data is not in ARC/L2ARC, it actually needs to go out to a HDD to pull the data in. If your read speeds are slower than your write speeds, it just means that the data being read wasn't in cache. If you expected that data to be in the working set, perhaps your working set is too small.
12) Make sure your drives aren't SMR.
Shingled magnetic recording drives are generally unsuitable for FreeNAS and ZFS, but are particularly horrible for block storage due to the need to be rewriting small blocks in the middle of random tracks. If you use SMR for block storage, expect it to suck. Sorry. No gentle way to say it.
13) Use an appropriate network.
Bear in mind that if you are using 1Gbps ethernet, you are not going to see a lot of speed to your disk subsystem. Even if you do two of them, this only works out to 250MBytes/sec, about the speed of a single SATA HDD. It is usually advisable to be using a network that is at least 10Gbps with high quality network cards. Initiators often offer the ability to do round robin, but for this to work correctly, you need to have a properly designed network. This means two or more separate networks.
Additional reading: Multiple network interfaces on a single subnet
14) Don't ignore timeouts.
iSCSI initiators expect a snappy response from the iSCSI target. A connection that goes idle for five seconds is typically reset by the protocol. A poorly implemented iSCSI storage system using ZFS can exceed that in a number of ways. If you don't have sufficient CPU, if you don't have sufficient memory, if you don't have a fast enough network, if you have too many VM's competing for resources, if you have too much fragmentation, all of these things can cause iSCSI timeouts. These are a warning that you're under-resourced and in a position where you might eventually fail.
