squeakybadger
Dabbler
- Joined
- Feb 10, 2020
- Messages
- 13
Hi all,
I had a drive error out over the weekend, and the spare kicked it and resilvered.
I've added a new drive in and want to replace the bad one, but I'm not sure which drive to actually replace.
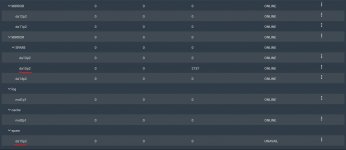
Is it the one the has 2.67k errors? Because that looks like the spare that is in use.
Attached the GUI disk layout to be clearer - da15p2 is the spare, but also seems to be the one with errors?
Any help appreciated!
Thanks.
I had a drive error out over the weekend, and the spare kicked it and resilvered.
I've added a new drive in and want to replace the bad one, but I'm not sure which drive to actually replace.
Code:
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: resilvered 7.76T in 22:26:53 with 0 errors on Tue Jan 24 02:39:51 2023
config:
NAME STATE READ WRITE CKSUM
PIK ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gptid/f9a1f0a4-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
gptid/fc5af3f5-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/fb22ecaf-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
gptid/fca8490e-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
gptid/fd35db7d-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
gptid/fd5df32a-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
mirror-3 ONLINE 0 0 0
gptid/fafe6574-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
gptid/fce2c376-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
mirror-4 ONLINE 0 0 0
gptid/fbf3c2f9-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
gptid/fc51679c-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
mirror-6 ONLINE 0 0 0
gptid/b97214c0-16c0-11eb-92ce-90e2ba89e89c ONLINE 0 0 0
gptid/94402ea8-0af9-11eb-b080-90e2ba89e89c ONLINE 0 0 0
mirror-7 ONLINE 0 0 0
spare-0 ONLINE 0 0 0
gptid/368d862f-16c3-11eb-92ce-90e2ba89e89c ONLINE 0 0 0
gptid/3768867b-16c3-11eb-92ce-90e2ba89e89c ONLINE 0 0 2.67K
gptid/378cdb9b-16c3-11eb-92ce-90e2ba89e89c ONLINE 0 0 0
logs
gptid/7eab73f1-b495-11ea-b2c1-90e2ba89e89c ONLINE 0 0 0
cache
gptid/f78b4cbc-b21c-11ea-98b6-90e2ba89e89c ONLINE 0 0 0
spares
gptid/3768867b-16c3-11eb-92ce-90e2ba89e89c INUSE currently in use
errors: No known data errorsIs it the one the has 2.67k errors? Because that looks like the spare that is in use.
Attached the GUI disk layout to be clearer - da15p2 is the spare, but also seems to be the one with errors?
Any help appreciated!
Thanks.