Hi,
Like the title's saying, whenever I am inside a pod, I cannot ping my internal network. And because of this issue, my pod is not able to resolve my internal DNS.
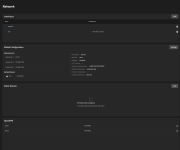
I am using an internal DNS in my home, all my devices and computers, including Scale, can resolve the DNS using my AdguardHome server.
However, when I am inside a pod, for e.g emby, and I want to resolve a DNS inside my home, the pod cannot communicate with my internal DNS server.
Ping from inside the emby pod:
Ping from the scale host:
The host is able to ping my local devices, but the pods are not.
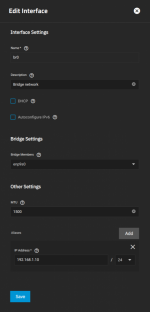
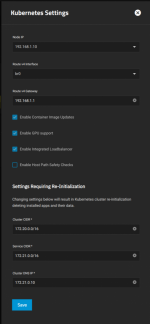
Anyone encounter this type of issue before? Is there a policy setup within the k3s to stop communicating with anything which is on the 192.168.1.0/24 subnet?
Regards,
Like the title's saying, whenever I am inside a pod, I cannot ping my internal network. And because of this issue, my pod is not able to resolve my internal DNS.
I am using an internal DNS in my home, all my devices and computers, including Scale, can resolve the DNS using my AdguardHome server.
However, when I am inside a pod, for e.g emby, and I want to resolve a DNS inside my home, the pod cannot communicate with my internal DNS server.
Ping from inside the emby pod:
Code:
I have no name!@emby-555474f-5x2gd:/app$ ping 192.168.1.1 PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data. 64 bytes from 192.168.1.1: icmp_seq=1 ttl=63 time=1.27 ms 64 bytes from 192.168.1.1: icmp_seq=2 ttl=63 time=0.562 ms 64 bytes from 192.168.1.1: icmp_seq=3 ttl=63 time=0.611 ms 64 bytes from 192.168.1.1: icmp_seq=4 ttl=63 time=0.562 ms ^C --- 192.168.1.1 ping statistics --- 4 packets transmitted, 4 received, 0% packet loss, time 3039ms rtt min/avg/max/mdev = 0.562/0.752/1.274/0.301 ms I have no name!@emby-555474f-5x2gd:/app$ ping 192.168.1.254 PING 192.168.1.254 (192.168.1.254) 56(84) bytes of data. ^C --- 192.168.1.254 ping statistics --- 3 packets transmitted, 0 received, 100% packet loss, time 2037ms I have no name!@emby-555474f-5x2gd:/app$ ping 192.168.1.253 PING 192.168.1.253 (192.168.1.253) 56(84) bytes of data. ^C --- 192.168.1.253 ping statistics --- 3 packets transmitted, 0 received, 100% packet loss, time 2050ms I have no name!@emby-555474f-5x2gd:/app$ ping 192.168.1.60 PING 192.168.1.60 (192.168.1.60) 56(84) bytes of data. ^C --- 192.168.1.60 ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 1031ms
Ping from the scale host:
Code:
root@truenas[~]# ping 192.168.1.1 PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data. 64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=0.874 ms 64 bytes from 192.168.1.1: icmp_seq=2 ttl=64 time=1.22 ms --- 192.168.1.1 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1008ms rtt min/avg/max/mdev = 0.874/1.047/1.220/0.173 ms root@truenas[~]# ping 192.168.1.254 PING 192.168.1.254 (192.168.1.254) 56(84) bytes of data. 64 bytes from 192.168.1.254: icmp_seq=1 ttl=64 time=0.201 ms 64 bytes from 192.168.1.254: icmp_seq=2 ttl=64 time=0.307 ms --- 192.168.1.254 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1014ms rtt min/avg/max/mdev = 0.201/0.254/0.307/0.053 ms root@truenas[~]# ping 192.168.1.253 PING 192.168.1.253 (192.168.1.253) 56(84) bytes of data. 64 bytes from 192.168.1.253: icmp_seq=1 ttl=64 time=0.157 ms 64 bytes from 192.168.1.253: icmp_seq=2 ttl=64 time=0.250 ms --- 192.168.1.253 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1032ms rtt min/avg/max/mdev = 0.157/0.203/0.250/0.046 ms --- 192.168.1.60 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1002ms rtt min/avg/max/mdev = 0.089/0.114/0.140/0.025 ms root@truenas[~]# ping 192.168.1.60 PING 192.168.1.60 (192.168.1.60) 56(84) bytes of data. 64 bytes from 192.168.1.60: icmp_seq=1 ttl=64 time=0.103 ms 64 bytes from 192.168.1.60: icmp_seq=2 ttl=64 time=0.110 ms 64 bytes from 192.168.1.60: icmp_seq=3 ttl=64 time=0.128 ms
The host is able to ping my local devices, but the pods are not.
Anyone encounter this type of issue before? Is there a policy setup within the k3s to stop communicating with anything which is on the 192.168.1.0/24 subnet?
Regards,