
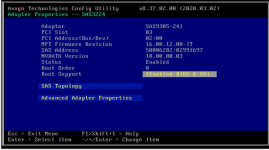
Is there a way to find this out within truenas or do i nees to press ctrl C on boot to go to the hba bios?What firmware is on that HBA?
Ok, so i copied some files from the pool and a ton of those errors I posted above appeared in dmesg for DA11 the count for UDMA CRC Errors now went up to 51 on that drive i swapped around. The original FAULTED drive values have not been affected. Definitely something up with that slot. I will swap the cables round on that row with another row and see if it affects any drive there.
EDIT
Added the images
Attachments
Last edited: