Hi all,
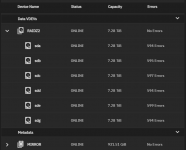
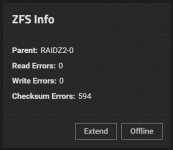
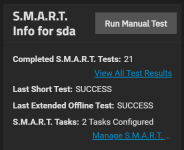
I get hundrets of checksum errors on my main pool after scrub. Nearly the same number for each disk. SMART runs weekly and reports disks are fine. I moved a lot of files to the pool recently.
Theory: Files were already corrupted when I moved them to the pool.
My Question: How do I find the affected files?
Using SMB to access from windows machine.
Thanks for your help!
I get hundrets of checksum errors on my main pool after scrub. Nearly the same number for each disk. SMART runs weekly and reports disks are fine. I moved a lot of files to the pool recently.
Theory: Files were already corrupted when I moved them to the pool.
My Question: How do I find the affected files?
Using SMB to access from windows machine.
Thanks for your help!