I agree but until @anodos releases the SMB patch which fixes the current issues with specific datasets, what is your proposed fix? If you take the time to set the correct dataset permissions, this is a good temporary solution.
I totally understand your frustration. I share
similar frustrations with different issues. I think in a lot of ways, they are trying to build the plane while it's in the air, and we are seeing the results of that here.
The way I see it, there are a host of ways to "solve" the problem but it really depends on the quantity and size of the datasets we are talking about. The parameters of the solution need to be consistent with the workflow in question.
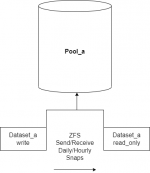
As an example, lets imagine you have a dataset which needs to be accessed by several programs, but is only ever written to by a single application. If the dataset is small enough, you could use ZFS send/receive. If you have enough RAM, you could even do deduplication to minimize the loss in storage.
This type of deployment would be fine for something like radarr and Plex, as an example of one of the things
@mervincm in this thread mentioned. Plex is capable of looking inside of nested folders for things, and from Plex's perspective over SMB, the nested dataset is just a nested folder.
So if "dataset_a_read_only" is nested inside of dataset _b, your Public Domain torrented, or otherwise legally obtained videos inside of that nested dataset will show up. Once you've seeded to the ratio you want, you can move the files from dataset_a_write to dataset_b. Snapshots will replicate, and they will be removed from dataset_a_read_only, so Plex won't have duplicates.
You can have SMB enabled on dataset_b by doing it this way. No more ACL problems, since it is literally a different dataset.
This also gives you a bit more power in terms of keeping an eye on how long you are allowing folks from the internet to connect back to you through whatever torrent swarms you are in.
Also, for the record, I think that containerizing applications that need access to a common set of data makes things unnecessarily complex. If you were to simply host all of the things that need access to a certain dataset inside of a single VM, alot of these problems would go away.