The fact that your system has to grab swap is showing you that there is a problem. Mainly insufficient RAM.
What's interesting though is that you can see from the memory plot that there is a fair bit of time where it DOESN'T need to grab swap and then it would increase relatively suddenly and dramatically.
My understanding about the system was that ZFS would release the ZFS cache when other things on the system need or want to use the memory.
So far, what I
haven't been able to do is to be able to successfully complete an audit of the system in order to try and fully account for everything that's running under "services".
Based on the screenshots shown above, I am not sure why PID 297 python3.8 is taking up 1.5 GB of RAM for middlewared.
If I can't figure out what's "eating up" the RAM, then I can't really figure out why the system is grabbing swap.
My thought process is working backwards through a root cause analysis to try and figure out why "services" is consuming 13.3 GiB of RAM and maybe that's why it results in the system needing to grab swap.
Fix the RAM usage issue (if one exists), then I would fix the swap grab. (At least, in theory.)
My system is a dumb file server.
There are no VMs, no jails, nothing else running on it.
I have a iSCSI target for my Steam library.
NFS is so that I can have my Linux systems connect to the server.
How many active samba users?
One. Me.
One.
Are you aware that 16GB is the bare minimum that TrueNAS requires?
No, I wasn't aware of that, but then again, I was just repurposing an old dual Xeon E5310 server to be my TrueNAS server, so it was whatever the system came with when I bought it.
smbd getting reaped by oom killer doesn't mean that it's to blame.
What I don't understand is that if it is printing out error messages to
Code:
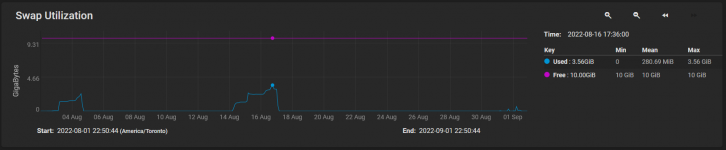
/var/log/console.log
, but there's supposed to be 10 GiB of swap available, why would the system say that it is out of swap when it has, at peak, only used up 3.56 GiB out of 10 GiB of swap?
I must be missing something because 3.56 GiB swap used out of 10 GiB of swap available
should not produce an "out of swap space" error. I don't understand why it is doing that. If the system was say at like 9.9 GiB swap used out of 10 GiB of swap available, then I can understand why it would be printing the "out of swap space" error message to
Code:
/var/log/console.log
.
But that's not the case here. So I don't really understand why it would be doing that at only 35.6% swap used, 64.4% swap free.
"services" in the GUI doesn't mean sharing services.
This is why I am trying to find out what all is in "services".
doesn't really seem to provide that answer as it lists only about 14 processes which only accounts for something like one-third of the total amount of RAM that's used by said "services".
For instance it can include page cache IIRC
So, I've implemented this script to page out what's in RAM to disk in order to prevent the kernel from crashing.
I tested hot-swap on my server that I'm commisioning today, and the kernel crashed because of this known issue https://forums.freenas.org/index.php?threads/swap-with-9-10.42749/ In response I've written a script: # This script is designed to page in used swap on any device that has swap in...

www.truenas.com
Your best bet is probably to update and see if it's still an issue.
Yeah, I'm still in the middle of backing up said ~33 TB of data before I can safely run the upgrade, just in case if something goes horribly wrong with said upgrade.
And if that doesn't work, I am getting ready to prep my old Core i7-6700K (which has 64 GB of RAM) to be my new TrueNAS server instead of using the dual Xeon that's almost 15 years old (the processors alone) by now.
And whilst my Core i7-6700K would be an almost 8 year old processor by now, it's still better than two almost-15-year-old processors.
I'm still puzzled by why this error state appears to be happening in the first place.
Your help is greatly appreciated.
Thank you.