NeWizz_
Dabbler
- Joined
- Feb 12, 2023
- Messages
- 10
Hi, I'm pretty new to TrueNas and Scale, so please bear with me and feel free to point out anything I should do differently.
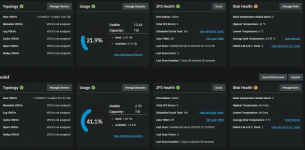
I just spotted that both my hdd's pools (4*seagate compute 1T and 4*seagate ironwolf 4T) were showing as 'unhealthy' in the GUI. I decided to start a manual long smartctl test using the GUI, which is ongoing on every one of those 8 drives, soon to find that was pointless.
After doing a bit of digging into it, I found out that the failed test happened a long time back (why didn't I spot it sooner is a mystery to me, maybe the update to TrueNAS-SCALE-22.12.1 is what allowed it to pop up?. So I logged into the server by ssh and used smartctl -x /dev/sd% in order to get all the relevant info for each of the affected drives. The failed test reports that it was interrupted (Extended offline Interrupted (host reset)), and therefore is simply a piece of information and not relevant to the health of said drives. The same drives cleared 7 smartctl scans since that happened, over the span of 900 hours of use.
So my question is, how do I clear that unhealthy flag from my GUI, as it's misleading and obstructing potentially important info if my pools were to really fail? I've looked around, and people mention a temporary folder for smart warnings but I can't find it.
Any help would be appreciated, thanks!
I just spotted that both my hdd's pools (4*seagate compute 1T and 4*seagate ironwolf 4T) were showing as 'unhealthy' in the GUI. I decided to start a manual long smartctl test using the GUI, which is ongoing on every one of those 8 drives, soon to find that was pointless.
After doing a bit of digging into it, I found out that the failed test happened a long time back (why didn't I spot it sooner is a mystery to me, maybe the update to TrueNAS-SCALE-22.12.1 is what allowed it to pop up?. So I logged into the server by ssh and used smartctl -x /dev/sd% in order to get all the relevant info for each of the affected drives. The failed test reports that it was interrupted (Extended offline Interrupted (host reset)), and therefore is simply a piece of information and not relevant to the health of said drives. The same drives cleared 7 smartctl scans since that happened, over the span of 900 hours of use.
So my question is, how do I clear that unhealthy flag from my GUI, as it's misleading and obstructing potentially important info if my pools were to really fail? I've looked around, and people mention a temporary folder for smart warnings but I can't find it.
Any help would be appreciated, thanks!