apnetworks
Cadet
- Joined
- Dec 7, 2021
- Messages
- 5
Hello,
I have been reading quite a few of the posts and from various sources it seems that the general consensus for highest IOPs and throughput is to run striped mirrored VDEVS ( a la RAID10 ) in an ISCSI as opposed to NFS flavor.
I am aware there is a new version of NFS4 but for various reasons ISCSI is just fine with me.
So I put me 12th gen double-cpu dell server to work with 64GB RAM and 8x2TB 7200 RPM 4kn Seagate Enterprise drives. Add me the ole read SSD cache and write SSD cache. (Could add more memory, but not sure it's justfied when the TrueNas Mini X+ is using 32GB and posting better reads with WD Red 5400 RPM drives)
Connected slot a on ESXi host to slot b on Truenas and mapped the ISCSI target / software ISCSI adapter using a 10Gbe link.
Ran the base install of Server 2016 off of the ISCSI share.
Put together some numbers with CrystalMark.

That's when I stopped and said .. hey.. Everyone else is getting 400 mb reads on average when they are doing their testing. FIO results from an Ubuntu VM for sequential read are abysmmal also.
Wondering if I am missing something here / how to troubleshoot that bottleneck.
From what I've read playing with the record block sizes isn't going to help as ZFS "bobs and weaves" and uses whatever block size it wants up to the limit that is set. Using smaller block sizes when appropriate.
Seeing as how VMware latest is using 1MB block sizes with 8KB sub-blocks I would assume sub-blocks are bring transferred in 8KB chunks. ISCSI is sending with the 1500MTU standard (not Jumbo) to the TrueNas storage over the 10GbE link.
So I would assume 1.5 KB chunks are flying across the wire 4-5 times for an esxi sub-block to a TrueNas unit that sees the 1.5 packets and puts them into 8 k chunks by sending them in two pieces to a 4kn drive?
That all gets very confusing and would seem to be the write process of things, which I am not having an issue with.
So reversing that process for reads would be - read two 4k sectors from drives, send them 1.5k at a time to vmware to assemble an 8kb sub-block.
Only options I have experimented with are - SLOG/NO SLOG - didn't make a difference (not worried about write performance right now so that was expected)
L2ARC cache SSD(s) - didn't make a difference
Disabled "Atime" on Zvol.
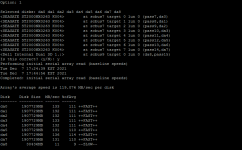
The metrics that I have performed have been within the ESXI environment and I am currently installing the Phoronix Test Suite directly onto the TrueNas server to test the drives outside of ISCSI connectivity.
I attempted to download and run the script from ftp.sol.net but links are broken. I have checked that with an FTP client and it is not there.

Any other recommendations to increase read performance for this setup?
I have been reading quite a few of the posts and from various sources it seems that the general consensus for highest IOPs and throughput is to run striped mirrored VDEVS ( a la RAID10 ) in an ISCSI as opposed to NFS flavor.
I am aware there is a new version of NFS4 but for various reasons ISCSI is just fine with me.
So I put me 12th gen double-cpu dell server to work with 64GB RAM and 8x2TB 7200 RPM 4kn Seagate Enterprise drives. Add me the ole read SSD cache and write SSD cache. (Could add more memory, but not sure it's justfied when the TrueNas Mini X+ is using 32GB and posting better reads with WD Red 5400 RPM drives)
Connected slot a on ESXi host to slot b on Truenas and mapped the ISCSI target / software ISCSI adapter using a 10Gbe link.
Ran the base install of Server 2016 off of the ISCSI share.
Put together some numbers with CrystalMark.
That's when I stopped and said .. hey.. Everyone else is getting 400 mb reads on average when they are doing their testing. FIO results from an Ubuntu VM for sequential read are abysmmal also.
Wondering if I am missing something here / how to troubleshoot that bottleneck.
From what I've read playing with the record block sizes isn't going to help as ZFS "bobs and weaves" and uses whatever block size it wants up to the limit that is set. Using smaller block sizes when appropriate.
Seeing as how VMware latest is using 1MB block sizes with 8KB sub-blocks I would assume sub-blocks are bring transferred in 8KB chunks. ISCSI is sending with the 1500MTU standard (not Jumbo) to the TrueNas storage over the 10GbE link.
So I would assume 1.5 KB chunks are flying across the wire 4-5 times for an esxi sub-block to a TrueNas unit that sees the 1.5 packets and puts them into 8 k chunks by sending them in two pieces to a 4kn drive?
That all gets very confusing and would seem to be the write process of things, which I am not having an issue with.
So reversing that process for reads would be - read two 4k sectors from drives, send them 1.5k at a time to vmware to assemble an 8kb sub-block.
Only options I have experimented with are - SLOG/NO SLOG - didn't make a difference (not worried about write performance right now so that was expected)
L2ARC cache SSD(s) - didn't make a difference
Disabled "Atime" on Zvol.
The metrics that I have performed have been within the ESXI environment and I am currently installing the Phoronix Test Suite directly onto the TrueNas server to test the drives outside of ISCSI connectivity.
I attempted to download and run the script from ftp.sol.net but links are broken. I have checked that with an FTP client and it is not there.
Any other recommendations to increase read performance for this setup?