
winnielinnie
MVP
- Joined
- Oct 22, 2019
- Messages
- 3,641
Without yet resorting to adding an L2ARC, is there a "tuneable" that I can test which instructs the ARC to prioritize metadata?
I upgraded from 16GB to 32GB ECC RAM.
Yet there is zero change in this behavior.
This keeps happening:
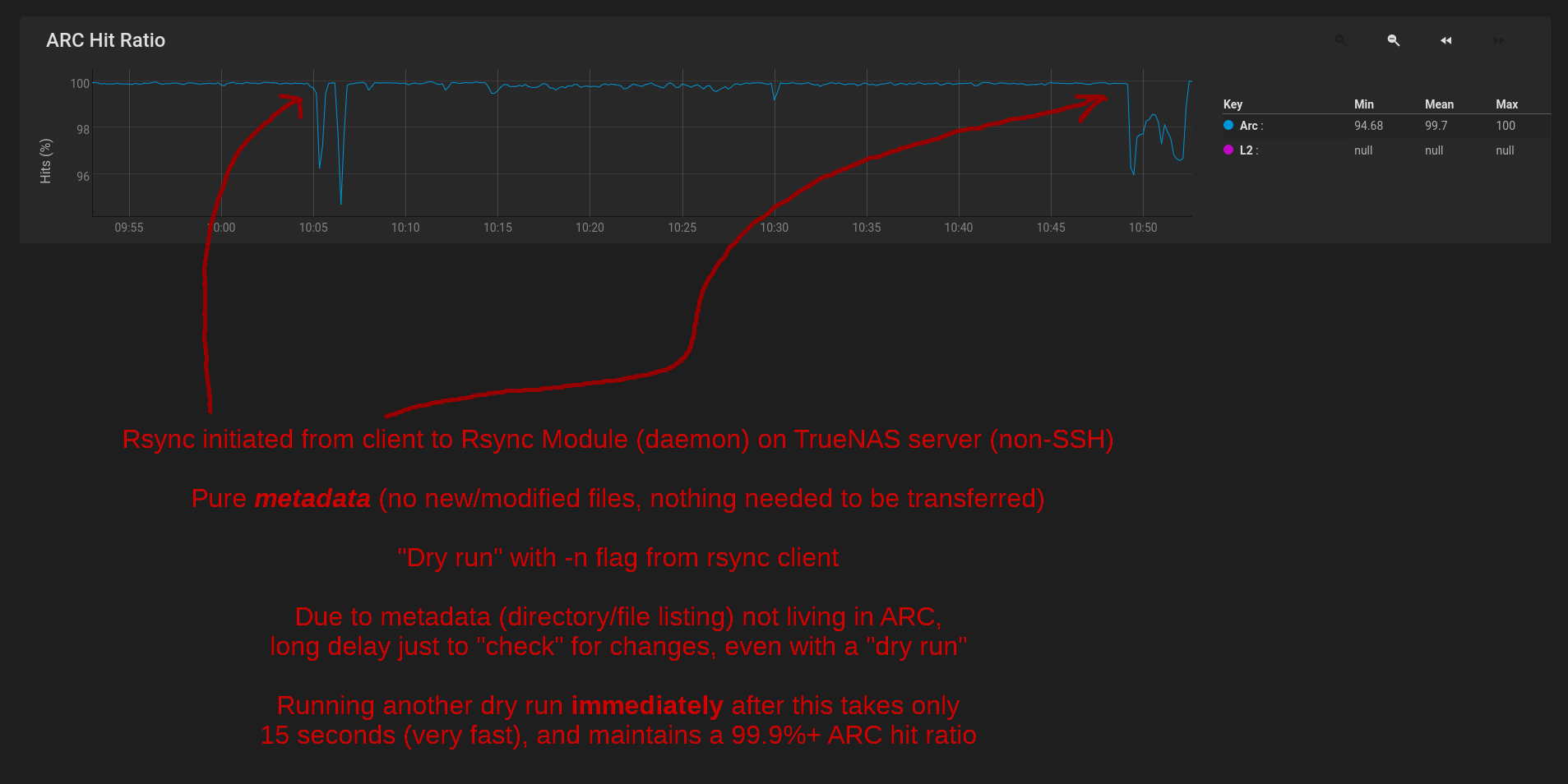
I run regular rsync tasks from a few local clients, which is very metadata heavy (not so much actual data involved). I assumed that over time ZFS would "intelligently" adjust the ARC to prevent the metadata in question from being evicted every day. Yes, it's a lot of metadata (many files/folders on the dataset), but it's accessed every day, and I would argue that the metadata of the filesystem gets more "hits" than some random data itself.
I've even been through a couple weeks of barely touching any files on the NAS server, and thus the only real usage of the NAS is to list the directory tree with rsync.
Is there some tweak or tuneable to instruct the ARC to prioritize metadata? Honestly, the NAS server would perform better (in my usage) if it evicted large caches of data blocks to make room for metadata instead.
I upgraded from 16GB to 32GB ECC RAM.
Yet there is zero change in this behavior.
This keeps happening:
I run regular rsync tasks from a few local clients, which is very metadata heavy (not so much actual data involved). I assumed that over time ZFS would "intelligently" adjust the ARC to prevent the metadata in question from being evicted every day. Yes, it's a lot of metadata (many files/folders on the dataset), but it's accessed every day, and I would argue that the metadata of the filesystem gets more "hits" than some random data itself.
I've even been through a couple weeks of barely touching any files on the NAS server, and thus the only real usage of the NAS is to list the directory tree with rsync.
Is there some tweak or tuneable to instruct the ARC to prioritize metadata? Honestly, the NAS server would perform better (in my usage) if it evicted large caches of data blocks to make room for metadata instead.



