A bit dramatic, but OK thanks.
Call it a friendly request not to make other people do your formatting. It'd be preferable to just not inline your comments at all. The forumware strips out previous replies in comments, so doing it the way that you did it makes it both very difficult to read, AND then when I reply, it would have wiped out the entire quoted message.
I didn't mean to leave that hanging. It was intended to be directly followed up by a more in-depth response, which I got busy and didn't provide. Sorry 'bout that.
The pool itself is 55% used but I did make the iSCSI dataset to be just a little bigger than the VMFS datastore sitting on it, so the datasets are closer to 99%. I can expand it if you think it will benefit it.
The dataset size is irrelevant because they're still part of the pool, and using the space on the pool.
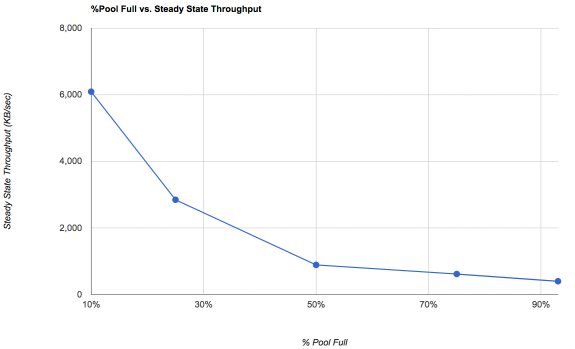
If you have a high degree of fragmentation, 55% is already going to be pathetically slow. The two variables here are the pool percent-full and the pool fragmentation. A pool that's 90% full and 0% fragmented will seem really fast. Over time, what happens in a copy-on-write (CoW) filesystem like ZFS is that you get a lot of fragmentation. Free space combats fragmentation. Over time, speeds will decrease until you get to a "steady state" where things settle into a "this is about as bad as it gets."
If we look at a graph of steady state performance on a single drive:
So, see, the thing here is that a single drive with random I/O on it would normally only be capable of maybe 150 IOPS or about 600KB/sec. What you'll notice is that ZFS is actually making it possible for that drive to go a lot faster for writes. But there are some caveats: first, ZFS treats sequential and random writes very similarly. Normally storage guys think of sequential and random I/O as very different things, but ZFS basically just looks for a nice contiguous run of blocks to allocate, and starts writing. What this means is that as a pool fills, both sequential and random write speeds suffer. It also means that fragmentation can become a significant performance problem. We mitigate the read performance issues associated with fragmentation by using lots of RAM (ARC) and L2ARC. We mitigate the write performance issue primarily by throwing lots of extra space at the pool.
Do note in particular that at 10% occupancy, a one disk pool, at its worst, is likely to seem a full TEN TIMES faster at random writes than the underlying storage device would be capable of in a normal environment.
The real world implications get hard to wrap your head around.
Because despite being asked that and second guessing myself each time, whenever I remove the l2arc I get worse performance. With an l2arc the MAX performance is slightly lower (2-3%), but overall I get consistent performance and higher average performance. After you posted this, I removed it and same results. (and still 40-60MB/s write).
That's kind of typical. People often think of the L2ARC as something to make their stuff go faster, but in reality if a single read is fulfilled from the L2ARC rather than the pool, you're not likely to be able to tell. The L2ARC is more usefully thought of as a tool to reduce the load on your pool, which will in turn make a very busy pool seem more responsive and tends to result in better performance for the stuff that's being used heavily. However, at only 32GB, you're also going to be stressing the available memory. We usually don't recommend L2ARC until you have at least 64GB of RAM. This is a complex thing, though, partially dependent on how much stuff you're actually using on the volume.
I mean I get sata vs nvme is significantly slower but 50-60MB/s slow? Pretty sure you could easily hit 200MB/s writes on these drives if not way higher.
Of course. An NVMe drive can hit gigabytes per second of writes. If that's all that was involved. It's not. A sync write starts at the client, and has to make a very complicated round trip, in lockstep, for EACH WRITE REQUEST. The "sync" part of "sync write" means that the client is requesting that the current data block be confirmed as written to disk before the write() system call returns to the client. Without sync writes, a client is free to just stack up a bunch of write requests and then they can send over a slowish channel, and they arrive when they can. Look at the layers:
Client initiates a write syscall
Client filesystem processes request
Filesystem hands this off to the network stack as NFS or iSCSI
Network stack hands this packet off to network silicon
Silicon transmits to switch
Switch transmits to NAS network silicon
NAS network silicon throws an interrupt
NAS network stack processes packet
Kernel identifies this as a NFS or iSCSI request and passes to appropriate kernel thread
Kernel thread passes request off to ZFS
ZFS sees "sync request", sees an available SLOG device
ZFS pushes the request to the SAS device driver
Device driver pushes to LSI SAS silicon
LSI SAS chipset serializes the request and passes it over the SAS topology
SAS or SATA SSD deserializes the request
SSD controller processes the request and queues for commit to flash
SSD controller confirms request
SSD serializes the response and pssses it back over the SAS topology
LSI SAS chipset receives the response and throws an interrupt
SAS device driver gets the acknowledgment and passes it up to ZFS
ZFS passes acknowledgement back to kernel NFS/iSCSI thread
NFS/iSCSI thread generates an acknowledgement packet and passes it to the network silicon
NAS network silicon transmits to switch
Switch transmits to client network silicon
Client network silicon throws an interrupt
Client network stack receives acknowledgement packet and hands it off to filesystem
Filesystem says "yay, finally, what took you so long" and releases the syscall, allowing the client program to move on.
That's what happens for EACH sync write request. It always amazes me that a network based storage solution can be doing that for each block and yet it is still possible, under optimal conditions, to get a few hundred MBytes/sec write speeds.
%Busy seems to bounce around 60-80.
Code:
dT: 10.001s w: 10.000s
L(q) ops/s r/s kBps ms/r w/s kBps ms/w %busy Name
0 0 0 0 0.0 0 0 0.0 0.0| da0
1 298 0 0 0.0 286 20039 0.7 56.9| da1
1 292 0 13 33.2 281 19564 0.8 62.1| da2
1 295 0 0 0.0 283 19732 1.1 67.4| da3
0 683 0 0 0.0 616 51257 2.2 22.8| da4
1 297 0 0 0.0 286 20052 0.7 54.7| da5
1 294 0 0 0.0 283 19718 0.9 63.7| da6
0 0 0 0 0.0 0 0 0.0 0.0| da0p1
0 0 0 0 0.0 0 0 0.0 0.0| da1p1
1 298 0 0 0.0 286 20039 0.7 57.0| da1p2
0 0 0 0 0.0 0 0 0.0 0.0| da2p1
1 292 0 13 33.2 281 19564 0.8 62.2| da2p2
0 0 0 0 0.0 0 0 0.0 0.0| da3p1
1 295 0 0 0.0 283 19732 1.1 67.5| da3p2
0 683 0 0 0.0 616 51257 2.2 22.8| da4p1
0 0 0 0 0.0 0 0 0.0 0.0| da5p1
1 297 0 0 0.0 286 20052 0.7 54.8| da5p2
0 0 0 0 0.0 0 0 0.0 0.0| da6p1
1 294 0 0 0.0 283 19718 0.9 63.8| da6p2
1 295 0 0 0.0 284 19860 0.9 65.7| da7
0 0 0 0 0.0 0 0 0.0 0.0| ada0
0 0 0 0 0.0 0 0 0.0 0.0| gptid/58b47d2e-efb1-11e4-9401-000c294bff6f
1 298 0 0 0.0 286 20039 0.7 57.1| gptid/1fee8dcf-d0fd-11e4-872a-000c294bff6f
0 0 0 0 0.0 0 0 0.0 0.0| da5p1.eli
1 292 0 13 33.2 281 19564 0.8 62.2| gptid/1e3962c7-d0fd-11e4-872a-000c294bff6f
0 0 0 0 0.0 0 0 0.0 0.0| da7p1.eli
1 295 0 0 0.0 283 19732 1.1 67.6| gptid/1ba2de10-d0fd-11e4-872a-000c294bff6f
0 683 0 0 0.0 616 51257 2.2 22.9| gptid/4d52bc10-efb1-11e4-9401-000c294bff6f
0 0 0 0 0.0 0 0 0.0 0.0| da1p1.eli
1 297 0 0 0.0 286 20052 0.7 54.9| gptid/1f1da057-d0fd-11e4-872a-000c294bff6f
0 0 0 0 0.0 0 0 0.0 0.0| da2p1.eli
1 294 0 0 0.0 283 19718 0.9 63.9| gptid/1d65cb0a-d0fd-11e4-872a-000c294bff6f
0 0 0 0 0.0 0 0 0.0 0.0| da7p1
1 295 0 0 0.0 284 19860 0.9 65.7| da7p2
0 0 0 0 0.0 0 0 0.0 0.0| ada0p1
0 0 0 0 0.0 0 0 0.0 0.0| ada0p2
0 0 0 0 0.0 0 0 0.0 0.0| da6p1.eli
1 295 0 0 0.0 284 19860 0.9 65.8| gptid/1c8b1ac3-d0fd-11e4-872a-000c294bff6f
0 0 0 0 0.0 0 0 0.0 0.0| gptid/93a63019-e683-11e5-8618-0cc47a08e0a0
0 0 0 0 0.0 0 0 0.0 0.0| da3p1.eli
That strikes me as probably a fair bit of fragmentation, where having some additional free space is probably the best solution to help increase performance.
The crap part about ZFS is that for VM storage, you really want to use mirrors, and with mirrors, if you have a resiliency goal of something like "a single disk failure shall not compromise redundancy" then that means three-way mirrors. Then ZFS only performs well if you have ~25-50% pool fill, so you end up in this sorta-unhappy space where to get 1TB of really good VM storage you might need 12TB of raw disk space (3 4TB disks at 25% full, mirrored 3 way). But on the other hand, it'll really fly if you go and do it right, and it will still be a lot less expensive than commercial solutions.