Brandito
Explorer
- Joined
- May 6, 2023
- Messages
- 72
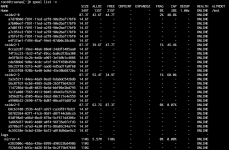
After adding a 4th 6 disk raidz2 to my 3 existing identical 6 disk raidz2 vdevs truenas is reporting they're mixed capacity.
I'm on 23.10.0.1. Tried the simplest thing which was to reboot but no change.
All of the drives are seagate exos 16tb x16's however one of the new drives is an x18 in the same 16tb capacity.
Is this something to be worried about, is it a known bug?
Update 11/22/23: This thread has moved beyond the original issue. I've experienced corruption on my zpool, particularly a single dataset that now refuses to mount when the pool is imported.
Nearly all hardware has been swapped (hba, sff cables, the server itself, and tried freebsd)
Currently have additional drives coming that can ingest all my data, just need some way to access it.
If you have any insights into what I might try to get the data out of my pool please let me know. I am open to suggestions
Also, thank you so much to everyone that has helped me get to the point where the pool imports and helping me come up with a plan to save everything I can
I'm on 23.10.0.1. Tried the simplest thing which was to reboot but no change.
All of the drives are seagate exos 16tb x16's however one of the new drives is an x18 in the same 16tb capacity.
Is this something to be worried about, is it a known bug?
Update 11/22/23: This thread has moved beyond the original issue. I've experienced corruption on my zpool, particularly a single dataset that now refuses to mount when the pool is imported.
Nearly all hardware has been swapped (hba, sff cables, the server itself, and tried freebsd)
Currently have additional drives coming that can ingest all my data, just need some way to access it.
If you have any insights into what I might try to get the data out of my pool please let me know. I am open to suggestions
Also, thank you so much to everyone that has helped me get to the point where the pool imports and helping me come up with a plan to save everything I can
Last edited: