Hello FreeNas community,
I am hoping for some assistance recovering a DEGRADED pool after battling with it for a week or so.
I am running FreeNAS 11.3-U5 with 1 RaidZ2 pool 'PaulsPool' which has 6x2TB drives via LSI 9211-8i IT Mode.
Background:
This system has been online and working without error for approx 1 year.
Approximately 6 months ago the original pool was 6x1TB
Problem:
Recently received an email alert that my pool was in a DEGRADED state.

However after I run an extended smartctl test and wait for it to complete I do not see any errors reported for the extended test?
Should I expect smartctl exteded test to align with reported FAULTED drive in FreeNAS?
For the drive that I am struggling to replace into the pool:
Is is possible I just have 3 bad 4TB Red Drives. (all ordered and arrived in the same package)?
Any guidance appreciated.
Thank you.
Regards,
Paul.
I am hoping for some assistance recovering a DEGRADED pool after battling with it for a week or so.
I am running FreeNAS 11.3-U5 with 1 RaidZ2 pool 'PaulsPool' which has 6x2TB drives via LSI 9211-8i IT Mode.
Background:
This system has been online and working without error for approx 1 year.
Approximately 6 months ago the original pool was 6x1TB
to increase capacity I used similar steps as below (OFFLINE,REPLACE,RESILVER) to replace each drive with 2TB, one at a time after resilver was complete in each case.
After migrating pool from 6x1TB to 6x2TB the pool has been working well.
I am mentioning this in case it is relevant to my problem below.
Problem:
Recently received an email alert that my pool was in a DEGRADED state.
- I connected to FreeNAS web UI and found pool 'PaulsPool' drive /dev/da5 was reporting FAULTED
- Attempting to run 'smartctrl -a /dev/da5' produced no results/output. (however provided expected results/output for other disks). I figured the disk was faulty.
- using smartctrl -a I confirmed serial numbers for all other disks and determined the physical faulty disk.
- I walked through the process of replacing the disk via https://www.ixsystems.com/documentation/freenas/11.3-U1/storage.html#replacing-a-failed-disk
- I can not remember exactly but I do not think the disk switched to "OFFLINE" state, however I did not receive any popup/error when I performed this step prior to removing the disk.
- In my subsequent re-attempts to resolve the DEGRADED pool I continue to try and OFFLINE the disk but it does not show any error but does not show OFFLINE state. It continues to show FAULTED.
- I now use the cli and issue zpool clear PaulsPool /dev/da5 and this will set it OFFLINE
- (perhaps these details are relevant to my problem)
- I powered down system and replaced the 2TB drive with a new WD 4TB Red drive.
- (I plan to eventually swap all the drives to 4TB once I can get this first FAULTED drive replaces successfully.)
- I powered back up server and went through the "Replace" steps via Web GUI.
- I confirmed that the drive offered for selection was in fact the new drive using smartctl -a to confirm serial number.
- The "Replace" completed successfully and then the PaulsPool status showed "ONLINE" and there is a "RESILVER Status: Scanning" in progress
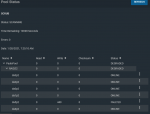
root@freenas[~]# zpool status PaulsPool
pool: PaulsPool
state: DEGRADED
status: One or more devices are faulted in response to persistent errors.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Replace the faulted device, or use 'zpool clear' to mark the device
repaired.
scan: scrub repaired 0 in 0 days 08:54:56 with 0 errors on Thu Jan 28 16:20:06 2021
config:
NAME STATE READ WRITE CKSUM
PaulsPool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
gptid/b4eb0a09-32ce-11ea-a9e6-e0d55eb3168e ONLINE 0 0 0
gptid/a2831277-31a1-11ea-a9e6-e0d55eb3168e ONLINE 0 0 0
gptid/4efa46b9-3274-11ea-a9e6-e0d55eb3168e ONLINE 0 0 0
gptid/e7ac2c9b-320c-11ea-a9e6-e0d55eb3168e ONLINE 0 0 0
gptid/e303cb9c-609e-11eb-88c1-e0d55eb3168e FAULTED 0 449 0 too many errors
gptid/a60b2095-13b9-11e9-ba42-e0d55eb3168e ONLINE 0 0 0
errors: No known data errors
root@freenas[~]#
However after I run an extended smartctl test and wait for it to complete I do not see any errors reported for the extended test?
Should I expect smartctl exteded test to align with reported FAULTED drive in FreeNAS?
root@freenas[~]# smartctl -a /dev/da5
smartctl 7.0 2018-12-30 r4883 [FreeBSD 11.3-RELEASE-p14 amd64] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Red (SMR)
Device Model: WDC WD40EFAX-68JH4N1
Serial Number: WD-WX12D80JSFNJ
LU WWN Device Id: 5 0014ee 2bde5ad25
Firmware Version: 83.00A83
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5400 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Thu Jan 28 13:02:53 2021 EST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x00) Offline data collection activity
was never started.
Auto Offline Data Collection: Disabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: (41160) seconds.
Offline data collection
capabilities: (0x7b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 153) minutes.
Conveyance self-test routine
recommended polling time: ( 2) minutes.
SCT capabilities: (0x3039) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x002f 100 253 051 Pre-fail Always - 0
3 Spin_Up_Time 0x0027 100 253 021 Pre-fail Always - 0
4 Start_Stop_Count 0x0032 100 100 000 Old_age Always - 2
5 Reallocated_Sector_Ct 0x0033 200 200 140 Pre-fail Always - 0
7 Seek_Error_Rate 0x002e 200 200 000 Old_age Always - 0
9 Power_On_Hours 0x0032 100 100 000 Old_age Always - 85
10 Spin_Retry_Count 0x0032 100 253 000 Old_age Always - 0
11 Calibration_Retry_Count 0x0032 100 253 000 Old_age Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 2
192 Power-Off_Retract_Count 0x0032 200 200 000 Old_age Always - 0
193 Load_Cycle_Count 0x0032 200 200 000 Old_age Always - 1
194 Temperature_Celsius 0x0022 116 112 000 Old_age Always - 31
196 Reallocated_Event_Count 0x0032 200 200 000 Old_age Always - 0
197 Current_Pending_Sector 0x0032 200 200 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0030 100 253 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x0032 200 200 000 Old_age Always - 0
200 Multi_Zone_Error_Rate 0x0008 200 200 000 Old_age Offline - 0
SMART Error Log Version: 1
No Errors Logged
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Extended offline Completed without error 00% 85 -
# 2 Extended offline Completed without error 00% 53 -
# 3 Conveyance offline Completed without error 00% 51 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.
root@freenas[~]#
For the drive that I am struggling to replace into the pool:
- I have tried with 2 other new WD 4TB Red drives and I get same results as above?
- I have tried a different sata port/cable
- I have tried to bypass the LSI card and use motherboard onboard SATA port.
- I am getting same results with slightly different number of WRITE errors each time during Resilvering.
Is is possible I just have 3 bad 4TB Red Drives. (all ordered and arrived in the same package)?
Any guidance appreciated.
Thank you.
Regards,
Paul.