Demonitron
Cadet
- Joined
- Jul 23, 2022
- Messages
- 6
Good evening all, sorry that my first ever post here is going to be in the nature of "Halp, I think I broke something!", but...yeah, I think I did. Kind of.
I was reading around trying to stop my T110 PowerEdge server from accessing the SAS Pool every 5 seconds, regardless of being idle as far as network activity went, and fell across a suggestion of moving the System Dataset from the storage pool to the boot pool.
Found the button for doing exactly that, pressed it & got two errors that came up saying that moving had failed. Afraid I forgot to note down what the errors were but I do remember something in the realms of it telling me it was 'busy'.
With that in mind I thought perhaps a reboot would help un-busy whatever it was.
On reboot, the GUI shows that the System Dataset is indeed now on the boot pool, but the drives continue to be accessed every 5 seconds (+/- a few milliseconds), which I now understand to be 'ZFS flushing'? Bare with me, this is my first ZFS experience so...I'm learning as I go.
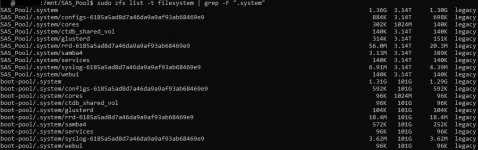
Anyway, the same thread that pointed me moving the System Dataset as a possible solution to my problem also gave a command for checking where it was located, with the 5 second access still happening I decided to give it a try & found that now I have my .system folder on BOTH the storage AND the boot pools.
What happened and...how do I fix it?
Other than this...hiccup, I am really, really loving TrueNAS Scale. I'm coming from a OMV 4.x system. I had intended on upgrading to OMV 6.x but it seems...clunky in comparison with it's older cousins. TrueNAS and it's originator FreeNAS have always terrified me since I know absolutely nothing about UNIX. Scale being Linux based has made trying it out a little less daunting (but ZFS is still scary!).
I was reading around trying to stop my T110 PowerEdge server from accessing the SAS Pool every 5 seconds, regardless of being idle as far as network activity went, and fell across a suggestion of moving the System Dataset from the storage pool to the boot pool.
Found the button for doing exactly that, pressed it & got two errors that came up saying that moving had failed. Afraid I forgot to note down what the errors were but I do remember something in the realms of it telling me it was 'busy'.
With that in mind I thought perhaps a reboot would help un-busy whatever it was.
On reboot, the GUI shows that the System Dataset is indeed now on the boot pool, but the drives continue to be accessed every 5 seconds (+/- a few milliseconds), which I now understand to be 'ZFS flushing'? Bare with me, this is my first ZFS experience so...I'm learning as I go.
Anyway, the same thread that pointed me moving the System Dataset as a possible solution to my problem also gave a command for checking where it was located, with the 5 second access still happening I decided to give it a try & found that now I have my .system folder on BOTH the storage AND the boot pools.
What happened and...how do I fix it?
Other than this...hiccup, I am really, really loving TrueNAS Scale. I'm coming from a OMV 4.x system. I had intended on upgrading to OMV 6.x but it seems...clunky in comparison with it's older cousins. TrueNAS and it's originator FreeNAS have always terrified me since I know absolutely nothing about UNIX. Scale being Linux based has made trying it out a little less daunting (but ZFS is still scary!).