fsfs% sudo smartctl -a /dev/ada5
smartctl 7.0 2018-12-30 r4883 [FreeBSD 11.3-RELEASE-p14 amd64] (local build)
Copyright (C) 2002-18, Bruce Allen, Christian Franke,
www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: HGST Ultrastar He6
Device Model: HGST HUS726060ALA640
Serial Number: [redacted]
LU WWN Device Id: 5 000cca 232d711ef
Firmware Version: AHGNT1EN
User Capacity: 6,001,175,126,016 bytes [6.00 TB]
Sector Size: 512 bytes logical/physical
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-2, ATA8-ACS T13/1699-D revision 4
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Wed Apr 7 01:03:39 2021 CDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED
General SMART Values:
Offline data collection status: (0x82) Offline data collection activity
was completed without error.
Auto Offline Data Collection: Enabled.
Self-test execution status: ( 0) The previous self-test routine completed
without error or no self-test has ever
been run.
Total time to complete Offline
data collection: ( 57) seconds.
Offline data collection
capabilities: (0x5b) SMART execute Offline immediate.
Auto Offline data collection on/off support.
Suspend Offline collection upon new
command.
Offline surface scan supported.
Self-test supported.
No Conveyance Self-test supported.
Selective Self-test supported.
SMART capabilities: (0x0003) Saves SMART data before entering
power-saving mode.
Supports SMART auto save timer.
Error logging capability: (0x01) Error logging supported.
General Purpose Logging supported.
Short self-test routine
recommended polling time: ( 2) minutes.
Extended self-test routine
recommended polling time: ( 998) minutes.
SCT capabilities: (0x003d) SCT Status supported.
SCT Error Recovery Control supported.
SCT Feature Control supported.
SCT Data Table supported.
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 016 Pre-fail Always - 0
2 Throughput_Performance 0x0005 131 131 054 Pre-fail Offline - 87
3 Spin_Up_Time 0x0007 160 160 024 Pre-fail Always - 646 (Average 597)
4 Start_Stop_Count 0x0012 100 100 000 Old_age Always - 23
5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 39
7 Seek_Error_Rate 0x000b 100 100 067 Pre-fail Always - 0
8 Seek_Time_Performance 0x0005 130 130 020 Pre-fail Offline - 12
9 Power_On_Hours 0x0012 098 098 000 Old_age Always - 16593
10 Spin_Retry_Count 0x0013 100 100 060 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 23
22 Helium_Level 0x0023 100 100 025 Pre-fail Always - 100
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 752
193 Load_Cycle_Count 0x0012 100 100 000 Old_age Always - 752
194 Temperature_Celsius 0x0002 162 162 000 Old_age Always - 37 (Min/Max 22/47)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
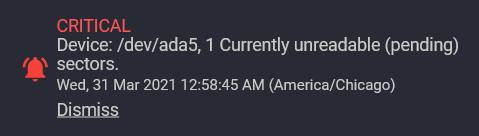
197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 1
198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline - 1
199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 0
SMART Error Log Version: 1
ATA Error Count: 1
CR = Command Register [HEX]
FR = Features Register [HEX]
SC = Sector Count Register [HEX]
SN = Sector Number Register [HEX]
CL = Cylinder Low Register [HEX]
CH = Cylinder High Register [HEX]
DH = Device/Head Register [HEX]
DC = Device Command Register [HEX]
ER = Error register [HEX]
ST = Status register [HEX]
Powered_Up_Time is measured from power on, and printed as
DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes,
SS=sec, and sss=millisec. It "wraps" after 49.710 days.
Error 1 occurred at disk power-on lifetime: 948 hours (39 days + 12 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
84 41 00 08 35 63 40 Error: ICRC, ABRT at LBA = 0x00633508 = 6501640
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
60 00 28 08 35 63 40 08 4d+14:42:08.245 READ FPDMA QUEUED
60 00 a0 08 44 63 40 08 4d+14:42:08.216 READ FPDMA QUEUED
60 00 98 08 43 63 40 08 4d+14:42:08.216 READ FPDMA QUEUED
60 00 90 08 42 63 40 08 4d+14:42:08.216 READ FPDMA QUEUED
60 00 88 08 41 63 40 08 4d+14:42:08.216 READ FPDMA QUEUED
SMART Self-test log structure revision number 1
Num Test_Description Status Remaining LifeTime(hours) LBA_of_first_error
# 1 Short offline Completed without error 00% 0 -
SMART Selective self-test log data structure revision number 1
SPAN MIN_LBA MAX_LBA CURRENT_TEST_STATUS
1 0 0 Not_testing
2 0 0 Not_testing
3 0 0 Not_testing
4 0 0 Not_testing
5 0 0 Not_testing
Selective self-test flags (0x0):
After scanning selected spans, do NOT read-scan remainder of disk.
If Selective self-test is pending on power-up, resume after 0 minute delay.