It's perfectly reasonable for people to verify I didn't overlook something: used ECC, no failed drives, scrubbed data before testing, etc.
But, I also kind of expect to be attacked ... bc if (and I'm not even saying this was caused by ZFS) it would make people depending on it anxious.
Irrespective where it happened (maybe I had a bad cable or the drive they came from had a problem) before transferring back to my TNC server.
I began discovering these a while ago and only recently realized just how many files it'd happened to.
Videos in my library (often the larger files) would just randomly stop and couldn't play past that point.
Many were ≥5GB, UHD, etc. Again, I can't say where the errors came from & have no way of knowing for sure.
MINIMIZING TIME WHILE (HYPOTHETICALLY) FIXING THESE FILES:
Rather than (HYPOTHETICALLY) torrenting the entire file ... one could (HYPOTHETICALLY)
- start a torrent of the exact same file
- once a data file emerged, pause the torrent
- replace the downloaded file with the corrupted file.
- Transmission at least (I think all) will see and scan the data and copy only what's required.
In most cases, this (HYPOTHETICALLY) cleaned the corruption yielding a good file in seconds to a few minutes.
Some did (hypothetically) take ≥40% to complete it.
I then realized I cannot know for certain the reported file size is correct, bc things like BT's "reserve" the capacity on the drive prior to DL-ing.
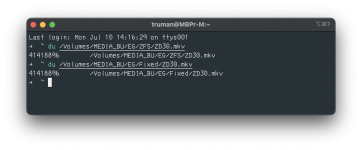
For this reason, I used "DU" command "disk usage" which calculates file space in 512-byte units.
There are still other possibilities, but, these were still equal also for the test file I chose for my example.
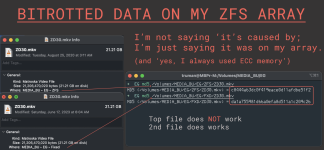
Bc the file's corrupt, had md5 been inadequate to show the discrepancy I'd've then used SHA or SHA256.
Pictures showing both the reported sizes and DU sizes were the same, and that only the md5 differed are attached.
But ... the files previously worked ... so it's pretty unlikely they were incomplete, and instead likely just had corrupted data.
I was definitely skeptical of my idea, bc there's no reason the BT protocol should be self-annealing.
Yes, filling in data that's missing is what it does ... but, I was surprised it replaced WRONG data.
Yes, it was exactly what I'd hoped it'd do ... but that didn't make it likely. It always seemed a tenuous solution.
But, I also kind of expect to be attacked ... bc if (and I'm not even saying this was caused by ZFS) it would make people depending on it anxious.
Irrespective where it happened (maybe I had a bad cable or the drive they came from had a problem) before transferring back to my TNC server.
I began discovering these a while ago and only recently realized just how many files it'd happened to.
Videos in my library (often the larger files) would just randomly stop and couldn't play past that point.
Many were ≥5GB, UHD, etc. Again, I can't say where the errors came from & have no way of knowing for sure.
MINIMIZING TIME WHILE (HYPOTHETICALLY) FIXING THESE FILES:
Rather than (HYPOTHETICALLY) torrenting the entire file ... one could (HYPOTHETICALLY)
- start a torrent of the exact same file
- once a data file emerged, pause the torrent
- replace the downloaded file with the corrupted file.
- Transmission at least (I think all) will see and scan the data and copy only what's required.
In most cases, this (HYPOTHETICALLY) cleaned the corruption yielding a good file in seconds to a few minutes.
Some did (hypothetically) take ≥40% to complete it.
I then realized I cannot know for certain the reported file size is correct, bc things like BT's "reserve" the capacity on the drive prior to DL-ing.
For this reason, I used "DU" command "disk usage" which calculates file space in 512-byte units.
There are still other possibilities, but, these were still equal also for the test file I chose for my example.
Bc the file's corrupt, had md5 been inadequate to show the discrepancy I'd've then used SHA or SHA256.
Pictures showing both the reported sizes and DU sizes were the same, and that only the md5 differed are attached.
But ... the files previously worked ... so it's pretty unlikely they were incomplete, and instead likely just had corrupted data.
I was definitely skeptical of my idea, bc there's no reason the BT protocol should be self-annealing.
Yes, filling in data that's missing is what it does ... but, I was surprised it replaced WRONG data.
Yes, it was exactly what I'd hoped it'd do ... but that didn't make it likely. It always seemed a tenuous solution.