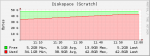
I use a UFS Volume for "scratch" temporary download writes, which get deleted afterward. After the data is written, it gets deleted. For some reason FreeNAS does not register the free disk space after the data is deleted. It seems like every 24 hours it does a new check and the available free disk space will be corrected.
Is there some sort of garbage collection that needs to happen after deletions? How do I get FreeNAS to correctly report the actual free disk space? This volume is being accessed through a jail, if that matters.
Note the difference between this and the screenshots:


Is there some sort of garbage collection that needs to happen after deletions? How do I get FreeNAS to correctly report the actual free disk space? This volume is being accessed through a jail, if that matters.
Note the difference between this and the screenshots:
Code:
$ du -sh /mnt/Scratch/ 3.6G /mnt/Scratch/
 FreeNAS-9.2.1.5-RELEASE-x64 (80c1d35)
FreeNAS-9.2.1.5-RELEASE-x64 (80c1d35)