
NickF
Guru
- Joined
- Jun 12, 2014
- Messages
- 763
Over the past year or so I have been obsessively exploring various aspects of ZFS performance, from large SATA arrays with multiple HBA cards, to testing NVME performance. In my previous testing I was leveraging castoff enterprise servers that were Westmere, Sandy Bridge and Ivy Bridge based platforms. There was some interesting performance variations between those platforms and I was determined to see what a more modern platform would do. It seemed that most of my testing indicated that ZFS was being bottlenecked by the platform it was running on, with high CPU usage being present during testing.
I recently picked up an AMD EPYC 7282, Supermicro H12SSL-I, and 256GB of DDR4-2133 RAM. While the RAM is certainly not the fastest, I now have a lot of PCIE lanes to play with and I don't have to worry as much about which slot goes to which CPUs.
For today's adventure, I tested 4 and 8 Samsung 9A1 512GB SSDs (PCIE Gen4), in 2 PLX PEX8747 (PCIE Gen3) Linkreal Quad M.2 adapter as well as 2 Bifurcation-based Linkreal Quad M.2 adapters in that new platform. My goal was to determine the performance differances between relying on motherboard bifurcation vs a PLX chip. I also wanted to test the performance impacts of compression and deduplication on NVME drives in both configurations. Testing was done using FIO, in a mixed read-and-write workload
I hope this helps some folks. :)
The first set of tests was done on single card with (4) 9A1s in a 2 VDEV mirrored configuration on each of the different cards.
The second set of tests was done with two matching cards with (8) 9A1s in a 4 VDEV mirrored configuration. The mirrors span between the cards, so if one entire card were to fail, the pool would remain in tact.
Some Bar Graphs:




Some interesting conclusions to be drawn :) The narrower 4 disk pools seem to perform better with the bifurcation based solution, which is likely due to the fact these are PCIE Gen 4 drives. However, as we get wider, the overhead of relying on the mainboard to do the switching seems to grow and the PLX chip solution seems to deliver better performance.
I recently picked up an AMD EPYC 7282, Supermicro H12SSL-I, and 256GB of DDR4-2133 RAM. While the RAM is certainly not the fastest, I now have a lot of PCIE lanes to play with and I don't have to worry as much about which slot goes to which CPUs.
For today's adventure, I tested 4 and 8 Samsung 9A1 512GB SSDs (PCIE Gen4), in 2 PLX PEX8747 (PCIE Gen3) Linkreal Quad M.2 adapter as well as 2 Bifurcation-based Linkreal Quad M.2 adapters in that new platform. My goal was to determine the performance differances between relying on motherboard bifurcation vs a PLX chip. I also wanted to test the performance impacts of compression and deduplication on NVME drives in both configurations. Testing was done using FIO, in a mixed read-and-write workload
fio --bs=128k --direct=1 --directory=/mnt/newprod/ --gtod_reduce=1 --ioengine=posixaio --iodepth=32 --group_reporting --name=randrw --numjobs=16 --ramp_time=10 --runtime=60 --rw=randrw --size=256M --time_based
I hope this helps some folks. :)
The first set of tests was done on single card with (4) 9A1s in a 2 VDEV mirrored configuration on each of the different cards.
| Test Setup | Read BW Min | Read BW max | Read BW Ave | Read BW Std Deviation | Read IOPs Min | Read IOPs max | Read IOPs Ave | Read IOPs Std Deviation | Write BW Min | Write BW max | Write BW Ave | Write BW Std Deviation | Write IOPs Min | Write IOPs max | Write IOPs Ave | Write IOPs Std Deviation |
| Bifurcation 4x9A1 2xMirrors with Dedupe and Compression | 142 | 7679 | 1163 | 103.88 | 1140 | 61437 | 9305 | 830.99 | 176 | 7642 | 1160 | 103.45 | 1414 | 61139 | 9282 | 827.56 |
| PLX 4x9A1 2xMirrors with Dedupe and Compression | 87 | 10065 | 1110 | 116.32 | 698 | 80264 | 8885 | 930.54 | 116 | 10064 | 1109 | 116.32 | 928 | 80264 | 8874 | 930.65 |
| Bifurcation 4x9A1 2xMirrors with Compression No Dedupe | 952 | 1967 | 1334 | 13.6 | 7621 | 15739 | 10655 | 95.55 | 1043 | 1931 | 1332 | 11.95 | 8346 | 15452 | 10655 | 95.55 |
| PLX 4x9A1 2xMirrors with Compression No Dedupe | 693 | 2031 | 1114 | 14.38 | 5548 | 16252 | 8918 | 115.05 | 777 | 2033 | 1112 | 13.29 | 6216 | 16264 | 8898 | 106.33 |
| Bifurcation 4x9A1 2xMirrors No Compression No Dedupe | 835 | 2471 | 1578 | 21.13 | 6686 | 6686 | 19770 | 168.97 | 857 | 2387 | 1579 | 20.02 | 6856 | 19098 | 12632 | 160.15 |
| PLX 4x9A1 2xMirrors No Compression No Dedupe | 692 | 1654 | 1091 | 13.01 | 5542 | 13232 | 8734 | 104.04 | 764 | 1574 | 1089 | 11.58 | 6114 | 12598 | 8716 | 92.66 |
The second set of tests was done with two matching cards with (8) 9A1s in a 4 VDEV mirrored configuration. The mirrors span between the cards, so if one entire card were to fail, the pool would remain in tact.
| Test Setup | Read BW Min | Read BW max | Read BW Ave | Read BW Std Deviation | Read IOPs Min | Read IOPs max | Read IOPs Ave | Read IOPs Std Deviation | Write BW Min | Write BW max | Write BW Ave | Write BW Std Deviation | Write IOPs Min | Write IOPs max | Write IOPs Ave | Write IOPs Std Deviation |
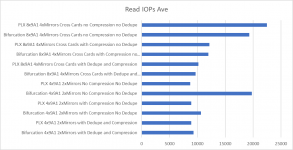
| Bifurcation 8x9A1 4xMirrors Cross Cards with Dedupe and Compression | 131 | 7641 | 1207 | 106.91 | 1055 | 61131 | 9658 | 855.27 | 171 | 7661 | 1204 | 106.68 | 1372 | 61294 | 9636 | 853.4 |
| PLX 8x9A1 4xMirrors Cross Cards with Dedupe and Compression | 285 | 6266 | 1273 | 89.59 | 2910 | 50290 | 10169 | 713.47 | 363 | 6286 | 1271 | 89.19 | 2910 | 50290 | 10169 | 89.19 |
| Bifurcation 8x9A1 4xMirrors Cross Cards with Compression no Dedupe | 1063 | 2092 | 1496 | 14.9 | 8506 | 16743 | 11968 | 108.81 | 1187 | 1979 | 1494 | 13.6 | 9500 | 15834 | 11959 | 108.81 |
| PLX 8x9A1 4xMirrors Cross Cards with Compression no Dedupe | 1074 | 2152 | 1519 | 14.8 | 8594 | 17217 | 12155 | 118.4 | 1241 | 2009 | 1518 | 13.29 | 9930 | 16075 | 12147 | 106.31 |
| Bifurcation 8x9A1 4xMirrors Cross Cards no Compression no Dedupe | 1664 | 3476 | 2412 | 22.98 | 13316 | 27809 | 19298 | 183.85 | 1741 | 3384 | 2415 | 172.6 | 13926 | 27077 | 19323 | 172.6 |
| PLX 8x9A1 4xMirrors Cross Cards no Compression no Dedupe | 2010 | 3718 | 2811 | 23.32 | 16082 | 29747 | 22490 | 186.51 | 2073 | 3594 | 2815 | 21.73 | 16588 | 28758 | 22524 | 173.81 |
Some Bar Graphs:
Some interesting conclusions to be drawn :) The narrower 4 disk pools seem to perform better with the bifurcation based solution, which is likely due to the fact these are PCIE Gen 4 drives. However, as we get wider, the overhead of relying on the mainboard to do the switching seems to grow and the PLX chip solution seems to deliver better performance.
Attachments
Last edited:




.PNG)



