David Dyer-Bennet
Patron
- Joined
- Jul 13, 2013
- Messages
- 286
My FreeNAS box, currently running whatever was the current release in the stable train late last week (it's locked up again as I started typing this), periodically becomes unresponsive. Sometimes it runs for several days of very light use without a problem, but when the weekly scrub of one of the pools comes along it hasn't lately made it through the scrub. Running a full backup of one pool to an external USB3 disk also rarely to never completes.
This current instance, it ran about 3 hours of the scrub (I've got a cron job that runs every 5 minutes and grabs the drive temps, and pushes them to another server, along with a graph for the last week; the scrub elevates drive and CPU temperatures enough that it's obvious when the scrub started (not high temps, but the drives idle at about 32C and jump to 35C during the scrub, and the CPU jumps nearly 15C, to 40C). In the past it runs longer sometimes, but it hasn't completed the scrub without becoming unresponsive for several weeks.
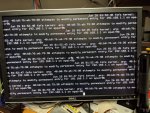
When it enters this bad state, the lights on the disk drives suggest that the scrub is still proceeding (constant activity on the disks in that pool, but not on other disks), the GUI is unresponsive, Samba shares are unresponsive, SSH is unresponsive, and the console is unresponsive. It can persist for more than 10 hours (my patience and my need for access to my data has so far blocked any longer experiments). CTRL-ALT_DEL from the keyboard has no effect, and pushing the power button briefly has no effect. Pushing reset, or forcing powerdown with a long power button push, works, and it reboots reasonably cleanly (and zpool status shows that the scrub completed without finding any errors). The console shows recent log activity when I view it while the system is unresponsive; it shows ARP errors "attempts to modify permanent entry for <server ip> on epair0b". I'm attaching a photo of the console, from an instance last week (but same message I'm seeing today), in case some detail is informative to someone else.
I've seen suggestions that power supply could be the issue. Some of this may relate to my having put one more disk drive in (this round of trouble started when I replaced a failing drive a month or two back; I also experimented with using a spare slot rather than USB for backup, and that drive is still present); then again it *first* came to my attention *before* I put the extra drive in. But maybe I'm on the ragged edge and the power supply is degrading, or something. Oh, I also disconnected one fan and installed another one (and the disk drive temps dropped significantly, they haven't been above 40C since then); but no net increase in fans so no big power draw change.
This system is years old and has been stable for most of that time. But degrading components happen, and I'd be happy if it's as simple as the power supply. The box currently has 6x6TB drives (one 3-way mirror, one 2-way mirror, and that drive I was attempting to make a backup onto; Hitachi, Toshiba, Whitelabel, maybe one other brand drive). Has ECC memory. Modern drives draw less and less power it looks like. MB is Asus M5A97LE R2.0, AMD FX-6300, 16GB ECC.
Any ideas on how to diagnose further? My problem, always, is that I'm maintaining this amount of data on an inadequate budget, and it's key data to me (decades of my photos, and a bit of other stuff), so replacing everything in sight at the first symptom of trouble isn't really an option.
This current instance, it ran about 3 hours of the scrub (I've got a cron job that runs every 5 minutes and grabs the drive temps, and pushes them to another server, along with a graph for the last week; the scrub elevates drive and CPU temperatures enough that it's obvious when the scrub started (not high temps, but the drives idle at about 32C and jump to 35C during the scrub, and the CPU jumps nearly 15C, to 40C). In the past it runs longer sometimes, but it hasn't completed the scrub without becoming unresponsive for several weeks.
When it enters this bad state, the lights on the disk drives suggest that the scrub is still proceeding (constant activity on the disks in that pool, but not on other disks), the GUI is unresponsive, Samba shares are unresponsive, SSH is unresponsive, and the console is unresponsive. It can persist for more than 10 hours (my patience and my need for access to my data has so far blocked any longer experiments). CTRL-ALT_DEL from the keyboard has no effect, and pushing the power button briefly has no effect. Pushing reset, or forcing powerdown with a long power button push, works, and it reboots reasonably cleanly (and zpool status shows that the scrub completed without finding any errors). The console shows recent log activity when I view it while the system is unresponsive; it shows ARP errors "attempts to modify permanent entry for <server ip> on epair0b". I'm attaching a photo of the console, from an instance last week (but same message I'm seeing today), in case some detail is informative to someone else.
I've seen suggestions that power supply could be the issue. Some of this may relate to my having put one more disk drive in (this round of trouble started when I replaced a failing drive a month or two back; I also experimented with using a spare slot rather than USB for backup, and that drive is still present); then again it *first* came to my attention *before* I put the extra drive in. But maybe I'm on the ragged edge and the power supply is degrading, or something. Oh, I also disconnected one fan and installed another one (and the disk drive temps dropped significantly, they haven't been above 40C since then); but no net increase in fans so no big power draw change.
This system is years old and has been stable for most of that time. But degrading components happen, and I'd be happy if it's as simple as the power supply. The box currently has 6x6TB drives (one 3-way mirror, one 2-way mirror, and that drive I was attempting to make a backup onto; Hitachi, Toshiba, Whitelabel, maybe one other brand drive). Has ECC memory. Modern drives draw less and less power it looks like. MB is Asus M5A97LE R2.0, AMD FX-6300, 16GB ECC.
Any ideas on how to diagnose further? My problem, always, is that I'm maintaining this amount of data on an inadequate budget, and it's key data to me (decades of my photos, and a bit of other stuff), so replacing everything in sight at the first symptom of trouble isn't really an option.