banancookie
Cadet
- Joined
- Apr 22, 2023
- Messages
- 2
Hi everyone, this is my first post.
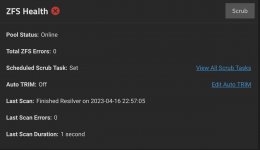
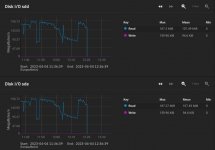
We have a problem with our TrueNAS Scale server. There is an automated scrub task on our mirrored pool named "main". However, this scrub never finishes and keeps hanging at circa 22% every time. The initial time estimation is about 3,5h, however, once this 22%-mark is reached the time estimation just increases to, hours, days, months or years, depending how long we keep it running. The scrub can't be stopped via the web ui or command line. When the scrub starts hanging, the disk IO goes to zero and the shown log appears in dmesg: "PANIC: fs: attempting to increase fill beyond max; probable double add in segment [2980f0ef000:298368e8000]" (see screenshots).
The pool consist of two mirrored HDDs, 2 WD Red Plus with 4TB. When we shut down the system, disconnect one of the HDDs and let the scrub run again, the scrub hangs again at ~22%.
A S.M.A.R.T. test did run successfully on the two HDDs without any errors. Scrubs run successfully on other pools without errors.
We upgraded from TrueNAS Core about a year ago to TrueNAS scale. We thought maybe something went wrong during the upgrade, so we recently did a fresh TrueNAS scale installation of TrueNAS-SCALE-22.12.2. After importing the pool and starting a new scrub, this one also hangs at ~22%.
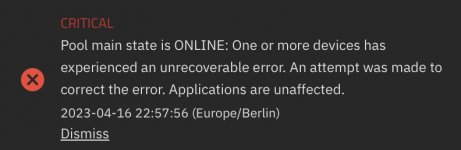
Recently, TrueNAS reported some errors (see attached images). To me, this sounds like a hardware error.
System information:
During our scrub tests, no other services were running. No system services like samba, dyndns, etc. and no vms were running
I don't know if these two "symptoms" (scrub hanging and samba not working), are related at all. However, especially the samba share problem renders the system mostly useless.
Is there anything else we can try or is this probably due to a hardware error in one of the WD Reds? They are not really old. They used to work fine, until around January of this year which is when the scrub problem arose. So it's not likely they were damage during transport and were broken in the first place.
Thanks in advance.
We have a problem with our TrueNAS Scale server. There is an automated scrub task on our mirrored pool named "main". However, this scrub never finishes and keeps hanging at circa 22% every time. The initial time estimation is about 3,5h, however, once this 22%-mark is reached the time estimation just increases to, hours, days, months or years, depending how long we keep it running. The scrub can't be stopped via the web ui or command line. When the scrub starts hanging, the disk IO goes to zero and the shown log appears in dmesg: "PANIC: fs: attempting to increase fill beyond max; probable double add in segment [2980f0ef000:298368e8000]" (see screenshots).
The pool consist of two mirrored HDDs, 2 WD Red Plus with 4TB. When we shut down the system, disconnect one of the HDDs and let the scrub run again, the scrub hangs again at ~22%.
A S.M.A.R.T. test did run successfully on the two HDDs without any errors. Scrubs run successfully on other pools without errors.
We upgraded from TrueNAS Core about a year ago to TrueNAS scale. We thought maybe something went wrong during the upgrade, so we recently did a fresh TrueNAS scale installation of TrueNAS-SCALE-22.12.2. After importing the pool and starting a new scrub, this one also hangs at ~22%.
Recently, TrueNAS reported some errors (see attached images). To me, this sounds like a hardware error.
System information:
- Motherboard make and model: ASRock Z87Pro4
- CPU make and model: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz
- RAM quantity: 24 GB (2x8GB, 2x4GB) non ecc
- Hard drives, quantity, model numbers, and RAID configuration, including boot drives:
- main pool: 2 WD Red Plus 4TB, WDC_WD40EFZX-68AWUN0, bought in Oct 2021
- boot-pool: Samsung_SSD_840_EVO_250GB
- Hard disk controllers: via mainboard
- Network cards: Intel e82585 (e1000)
During our scrub tests, no other services were running. No system services like samba, dyndns, etc. and no vms were running
I don't know if these two "symptoms" (scrub hanging and samba not working), are related at all. However, especially the samba share problem renders the system mostly useless.
Is there anything else we can try or is this probably due to a hardware error in one of the WD Reds? They are not really old. They used to work fine, until around January of this year which is when the scrub problem arose. So it's not likely they were damage during transport and were broken in the first place.
Thanks in advance.