devedse
Dabbler
- Joined
- Nov 7, 2022
- Messages
- 14
Introduction
Hello all,
I've been using TrueNAS for a bit now as a secondary backup server. I love the concept of ZFS so I wanted to play with it.
I'm running a server with 26x 1TB disks where 2 are being ran in ZFS-Mirror with the operating system and the other 24 are all in 1 pool with 3 disks of redundancy.
All disks are connected to an HBA slotted in one of the PCIe slots of the server. I did this because I when I initially connected them to the internal RAID controller (which could be flashed into HBA mode) I had some strange issues. Where eventually I also ended up in a scenario where the operating systems seemed to have corrupted.
For this new setup, the performance was great and everything worked fine.
After a while I chose to simply turn off the server when I'm not using it and every 2-3 weeks turn it backup to refresh my backup (last time I also ran a Scrub / kept it on for a few days because I heard that's good for ZFS health). (I have a more up to date backup on a secondary Synology NAS).
One of the disks is currently broken but I was planning on replacing that soon. (Again, no real important data on this thing)
The crash today
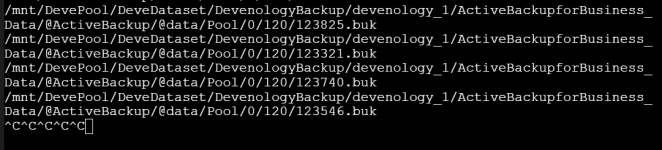
Today I turned the server on again and tried removing some snapshots because the disks were almost full (95%) which seemed to work fine. I also went to the Shell and deleted a directory that was taking up a lot of space.
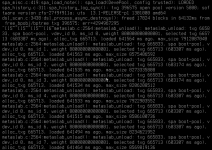
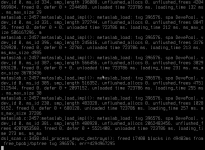
When I came back a few hours later the Web frontend was unavailable and the server itself was showing some strange information. I managed to trigger a shutdown which got stuck after unmounting 4 things (I don't remember the exact name) so after about 4 hours I did a cold reset.
The server is doing things
Now the server is doing all kinds of things but I have no idea if it's good or bad. Again, the data on the server isn't crucial but I'm curious what went wrong, how to fix it and what else I can do.
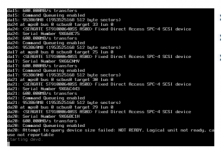
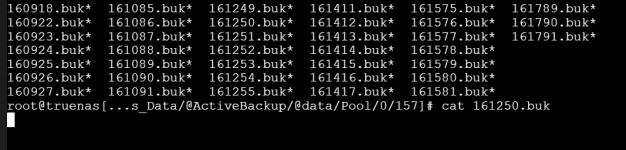
I attached screenshots 1 and 2 to show what the server displays now. I believe screenshot 3 is something from a few minutes earlier (harder to read since it's an iDRAC screenshot)
Does anyone have an idea what's going on here?
Hello all,
I've been using TrueNAS for a bit now as a secondary backup server. I love the concept of ZFS so I wanted to play with it.
I'm running a server with 26x 1TB disks where 2 are being ran in ZFS-Mirror with the operating system and the other 24 are all in 1 pool with 3 disks of redundancy.
All disks are connected to an HBA slotted in one of the PCIe slots of the server. I did this because I when I initially connected them to the internal RAID controller (which could be flashed into HBA mode) I had some strange issues. Where eventually I also ended up in a scenario where the operating systems seemed to have corrupted.
For this new setup, the performance was great and everything worked fine.
After a while I chose to simply turn off the server when I'm not using it and every 2-3 weeks turn it backup to refresh my backup (last time I also ran a Scrub / kept it on for a few days because I heard that's good for ZFS health). (I have a more up to date backup on a secondary Synology NAS).
One of the disks is currently broken but I was planning on replacing that soon. (Again, no real important data on this thing)
The crash today
Today I turned the server on again and tried removing some snapshots because the disks were almost full (95%) which seemed to work fine. I also went to the Shell and deleted a directory that was taking up a lot of space.
When I came back a few hours later the Web frontend was unavailable and the server itself was showing some strange information. I managed to trigger a shutdown which got stuck after unmounting 4 things (I don't remember the exact name) so after about 4 hours I did a cold reset.
The server is doing things
Now the server is doing all kinds of things but I have no idea if it's good or bad. Again, the data on the server isn't crucial but I'm curious what went wrong, how to fix it and what else I can do.
I attached screenshots 1 and 2 to show what the server displays now. I believe screenshot 3 is something from a few minutes earlier (harder to read since it's an iDRAC screenshot)
Does anyone have an idea what's going on here?