Whoops, I totally missed this thread...
Here my cents:
Here is some testing literature:
That literature isn't that great, because the ZSTD implementation in ZFS is not directly comparable with native ZSTD, performance wise.
I would suggest looking at my (older) performance tests on Linux.
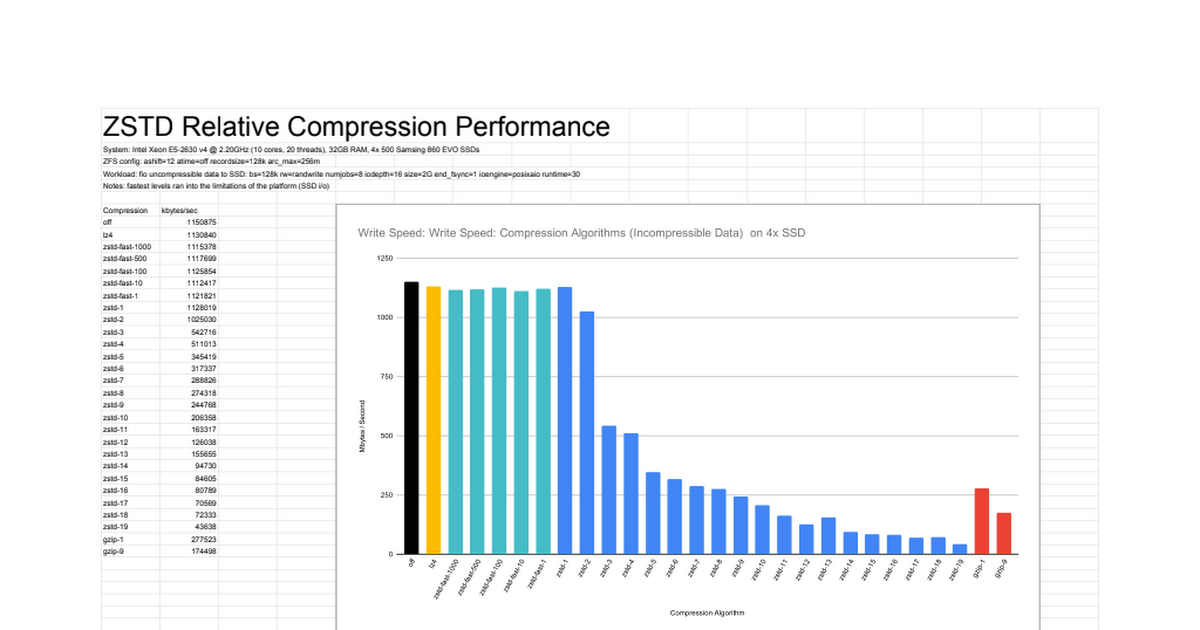
older numbers (slightly bottlenecked tests):
This PR introduces ZSTD compression to ZFS. Many thanks to: The original Proof of Concept by @allanjude see: #9024 The Linux compatibility redesign by @BrainSlayer see: #8941 Spin-off kvmem patch b...

github.com
Full latest test results by me:
This PR introduces ZSTD compression to ZFS. Many thanks to: The original Proof of Concept by @allanjude see: #9024 The Linux compatibility redesign by @BrainSlayer see: #8941 Spin-off kvmem patch b...
github.com
And the followup by Allan Jude:

docs.google.com
Short answer is that ZStd compresses more, but slower. LZ4 is faster.
Thats a simplification, because in a lot of cases the compression algorithm isn't the bottleneck.
Actually both me and Allan had/have trouble getting good numbers due to there being multiple bottlenecks when it comes to testing ZSTD within the whole ZFS stack.
Depending on things like recordsize and write pattern, both are perfectly capable of saturating more than a 10gb/s connection on a not-too-fast CPU (part of the threads from a 1700-non-k)
If you don't mind it being a little slower to access
It's actually the writes that are most affected by going from LZ4 to ZSTD, not the reads. As ZSTD is designed to be a LOT faster in decompression than it is to compress things. Unless you mean "access times", but I don't think we have specific numbers for it except iops.
the difference is not massive, the ZStd appears to offer better compression. If you are interested in fast access to the data, LZ4 appears to still be the fastest answer.
Thats an oversimplification because just because LZ4 is faster in most usecases, doesn't mean most people are actually pushing enough throughput to actually saturate their (spare) CPU (cycles) with ZSTD.
The correct answer would be something like:
"If you are running less than a modern 6 core intel CPU, with SSD based pools AND want to push multiple GB/s (thats bytes not bits) of either reads, writes or read-writes, ZSTD is not going to cut it"
Let me know if you need any help or compare notes. we're going to try some terminal servers on zstd level 3
Maybe let me know if
you need help. Okey just kidding ofcourse

- What are the server specs and the expected load (both writes, reads and iops) on said server?
- What are your expected dataset settings besides zstd? (primarily recordsize)
If it's mostly low blocksize reads, be aware a significant performance improvement to ZSTD is made in the latest 1.4.7 release.
I've just submitted the PR to said ZSTD version for ZFS yesterday:
Motivation and Context This change updates ZSTD to latest and provides some polish on the documentation. The update to ZSTD 1.4.8, among other things, enables us to remove our frame size patches Z...
github.com
Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz - 24 2TB - LSI 9207 - Intel 750 NVe - 64GB - Celios 10GB
is it the system in your signature?
In that case it's somewhat comparable to the system I used in my performance tests (except disks, performance tests where done using ramdisks).
You would really need to push your 10GB network card to its knees before you are going to be affected by performance limits of ZSTD in most usecases.
Thanks for the answers so far. I guess I'll stick with LZ4 then, as compression is not paramount and I'd rather avoid any performance degradation just to save a few gigs.
Thats why you shouldn't rely on generalised statements, all the answers do not account for your personal setup. Chances are you never would've had any performance degradation at all or would even have had a performance improvement (if you are bottlenecked by your disks and have lots of sequential data)
It has also been said that since the CPU is soooooo much faster than even SSDs, the bottleneck will not be the inline compression but rather the storage infrastructure. So that is promising.
That would be an oversimplification the other ware around.
With a 25Gb/s network card + 1 NVME SSD, it's possible to create a CPU bottleneck with a modern consumer intel 6-8 core CPU.
With harddisks you would be looking at A LOT of harddisks, but even then it is technically possible.
That being said: Those are not normal loads for most of us users, besides peak-load most important is the average load and spread of said load over the day, combined with peak expected load. It's quite likely that you wouldn't hit a CPU bottleneck, because you still need data to bottleneck on ;-)
For most systems, using compression actually makes them faster because of the speed factor you describe actually reducing the amount of work the mechanical disks need to do because the data is smaller. The comparison testing that has been done so far does show a compression benefit, but a small speed loss and I am not sure how noticeable that will be in practice because most people have a small enough pool of disks that their mechanical storage is still the slowest part of the chain and the absolute speed limiting factor. That said, if the data is smaller due to compression, the time to write (or read) it to and from the disk might be a little less. Will it be enough to notice a change for the user? In a large implementation it might save some space on disk. I plan to give it a try. I just wish it had been released a couple months earlier because I just finished bringing a new server online and the initial data load is already done.
Yes I agree here.
We shouldn't forget that in the age of LZ4 people where already rocking the same amount of HDD"s, with comparable amounts of total throughput, on much less powerfull CPU's. It would scale quite nicely into the future, just like lz4 did! :)
We made 2 changes.
1 updated to U1 and used the new compression. our performance is actually not as good. so i'm still evaluating.
Can you print out the CLI specs of your dataset and post it here?
I'd did not have difference with lz4 vs zstd7 which is strange. Even more so the data wasn't compressed with zstd7 at all..
ZSTD 7 is quite a bit higher than LZ4 in compression levels!
Mind to post a readout of you dataset specs?
You did try writhing new data write? Changing the compression level does NOT change data already writen to disk!
Wanted to try it out to see for myself on a test system.
Performance with both was equal. Pool usage with zstd higher plus UI showed a ration of 1.0...
Any ideas?
Ratio of 1.0 means "compression off"
Want to replace the max gzip pools with zstd to gain a bit more speed on the archives..
With higher levels of ZSTD you would even see an actual improvement on compression levels in a lot of cases :)
You don't need ZSTD-7 though, the performance decrease is much higher than the ratio increase per ZSTD level. I would suggest ZSTD-5, it's almost as good (and an improvement in both ratio and performance over GZIP) as ZSTD-7 but quite a bit faster
Ok, I was curious and created a 2nd pool with zstd (default level, 3) and replicated the pool. Space savings are 5.7% compared to LZ4. As I haven't used the 2nd pool, I cannot tell anything about the performance, though.
5.7% sounds like your data isn't highly compressable or your recordsize is low...
Something I'm trying to wrap my head around is if you change the compression option for a dataset that already has many files inside, do the existing blocks get re-written eventually (under-the-mood maintenance) with the new compression method?
No, they are not.
What if you modify an existing file? Does the copy-on-write write the new blocks with the updated compression method, or with the file's / block's original compression method?
They get rewriten with ZSTD :)
you can also send-recieve locally to force all data to be rewriten with ZSTD ;-)