Kevin Horton
Guru
- Joined
- Dec 2, 2015
- Messages
- 730
I'm trying to troubleshoot a kernel panic issue. The server had worked well for several years, but it KP'd overnight last night, and now panics within a minute or two after FreeNAS boots.
I've been able to look at /var/log in the brief periods before it panics, but haven't found anything yet that looks unusual. /data/crash has nothing new - it only has dumps from panics in 2016.
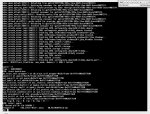
I recorded the console via IPMI, and a screen grab shows:

Does anyone see any clues in the KP console output above?
I reseated all data and power cables. I reseated the RAM sticks and the M1015. Still panics.
I tried reverting to an older FreeNAS boot environment (FN 11.3-U3). Still panics.
I tried booting without the data disks installed. Still panics.
Now I'm testing RAM using MemTest86. I figure that should rule out RAM, and partially rule out the CPU. If the RAM looks OK after one full pass, I'll do a CPU stress test with mprime. If that passes, I'll temporarily remove the M1015. If it still panics, I'll try moving the OS to a USB stick (only for testing) to rule out the SSD.
Any advice is appreciated.
Thanks,
Kevin
System Config:
FreeNAS 11.3-U5
Supermicro X10SRH-cF with E5-1650v4 CPU.
RAM: 96 GB (2 x Samsung 32GB M393A4K40BB0-CPB + 2 x Samsung 16GB M393A2G40DB0-CPB)
Boot drive: SanDisk Plus 120GB connected to M1015
HBA: M1015 flashed to IT mode, with firmware 20.00.07.00
PSU: 860W SeaSonic SS-860-XP2 Platinum
Data disks: 2 pools, each consisting of 8 x WB Red WD40EFRX 4TB in RAIDZ2
Chassis: Norco RPC-4224
I've been able to look at /var/log in the brief periods before it panics, but haven't found anything yet that looks unusual. /data/crash has nothing new - it only has dumps from panics in 2016.
I recorded the console via IPMI, and a screen grab shows:
Does anyone see any clues in the KP console output above?
I reseated all data and power cables. I reseated the RAM sticks and the M1015. Still panics.
I tried reverting to an older FreeNAS boot environment (FN 11.3-U3). Still panics.
I tried booting without the data disks installed. Still panics.
Now I'm testing RAM using MemTest86. I figure that should rule out RAM, and partially rule out the CPU. If the RAM looks OK after one full pass, I'll do a CPU stress test with mprime. If that passes, I'll temporarily remove the M1015. If it still panics, I'll try moving the OS to a USB stick (only for testing) to rule out the SSD.
Any advice is appreciated.
Thanks,
Kevin
System Config:
FreeNAS 11.3-U5
Supermicro X10SRH-cF with E5-1650v4 CPU.
RAM: 96 GB (2 x Samsung 32GB M393A4K40BB0-CPB + 2 x Samsung 16GB M393A2G40DB0-CPB)
Boot drive: SanDisk Plus 120GB connected to M1015
HBA: M1015 flashed to IT mode, with firmware 20.00.07.00
PSU: 860W SeaSonic SS-860-XP2 Platinum
Data disks: 2 pools, each consisting of 8 x WB Red WD40EFRX 4TB in RAIDZ2
Chassis: Norco RPC-4224