herr_tichy
Dabbler
- Joined
- Jul 14, 2014
- Messages
- 12
Hi,
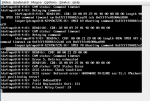
About an hour ago, one of my disks died - FreeNAS noticed something was wrong (see attachment), but took over 30 minutes to finally remove it from the ZFS (raid-Z3) pool. In that time, the machine was completely unresponsive, NFS didn't work and the iSCSI target for the VMware cluster became unavailable.
This is a bit useless. Is there any way to make FreeNAS remove failing disks from the pool faster so I don't get downtime? That is kind of the point of having a RAID, isn't it....
About an hour ago, one of my disks died - FreeNAS noticed something was wrong (see attachment), but took over 30 minutes to finally remove it from the ZFS (raid-Z3) pool. In that time, the machine was completely unresponsive, NFS didn't work and the iSCSI target for the VMware cluster became unavailable.
This is a bit useless. Is there any way to make FreeNAS remove failing disks from the pool faster so I don't get downtime? That is kind of the point of having a RAID, isn't it....