I've finally found the Archive flag that allowed me to RSYNC at least somewhat successfully to our new server. There's a couple of issues though that I was wondering if I could get help with.
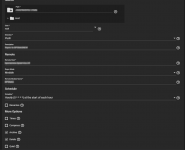
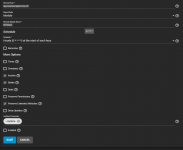
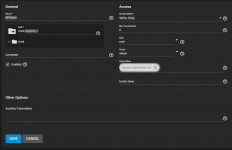
What exactly does Access Mode under the RSYNC module do. Is it Access Mode from the source to the destination? i.e. if I change it from RW which is how I set it up initially to Read, will it not be able to write to the target server? If true, I don't understand if the module is the target why the default is Read for rsync modules.
Even though I have it running as root on the target server, with my full rsync last night it failed with the following errors on only two different data sets.
rsync: [generator] failed to set permissions on "<full file path>" (in <Source Server>): Operation not permitted (1)
and
rsync: [receiver] failed to set permissions on "<full file path>" (in <Source Server>): Operation not permitted (1)
Does this indicate that the rsync is trying to set permission on the Source Server or is indicating that it can't set them FROM the source server?
Is there anything I can do to correct it to make sure I get a full sync including permissions?
What exactly does Access Mode under the RSYNC module do. Is it Access Mode from the source to the destination? i.e. if I change it from RW which is how I set it up initially to Read, will it not be able to write to the target server? If true, I don't understand if the module is the target why the default is Read for rsync modules.
Even though I have it running as root on the target server, with my full rsync last night it failed with the following errors on only two different data sets.
rsync: [generator] failed to set permissions on "<full file path>" (in <Source Server>): Operation not permitted (1)
and
rsync: [receiver] failed to set permissions on "<full file path>" (in <Source Server>): Operation not permitted (1)
Does this indicate that the rsync is trying to set permission on the Source Server or is indicating that it can't set them FROM the source server?
Is there anything I can do to correct it to make sure I get a full sync including permissions?