UserFriendlyyy
Cadet
- Joined
- Jan 17, 2023
- Messages
- 3
Being new to all this, I started to set up my first data set and saw deduplication as an option and thought "Wonderful, I have at least 200gb of duplicate files,” and with 16gb of ram I wasn't too worried about the performance hit that popped up to warn me. I even dedicated a 500gb ssd for dedup tables. After importing a bit under 3tb to the pool I could see the performance hit and did a bit of googling to figure out that dedup doesn't even do what I thought it did and would basically make my system almost unusable. (a little popup to explain some of the options while you are trying to set them up would have been very helpful.).
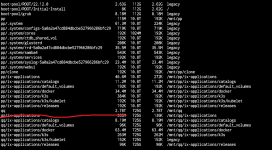
I decided to copy back the files and nuke the dataset so I could start over. Since there is no good way I could find to export data back to ntfs (which had already been wiped and added to the pool) I decided to use "replication task" to back up my data so I could nuke the pool and then rebuild it without deduplication. I make a new pool, saw that the replication compiled successfully, nuked pool 1 and now I have no idea how to get the data back. I'm using scale BTW and everything I have read and seen about restoring from a replication looks like they were using CORE because I don't see any of the options they are using. I also have no experience with Linux or BSD, I'm ok on DOS though, so its more a matter of just not knowing any of the commands.
Stupidly, I replicated it right to the top level of the 2nd pool, which is probably a large part of why I'm struggling here.
At this point, even if I could restore the old pool and copy the data off the very vey very slow way I would be fine with it.
Thanks for taking the to time to read all this, and especially if you have any suggestions to help.
I decided to copy back the files and nuke the dataset so I could start over. Since there is no good way I could find to export data back to ntfs (which had already been wiped and added to the pool) I decided to use "replication task" to back up my data so I could nuke the pool and then rebuild it without deduplication. I make a new pool, saw that the replication compiled successfully, nuked pool 1 and now I have no idea how to get the data back. I'm using scale BTW and everything I have read and seen about restoring from a replication looks like they were using CORE because I don't see any of the options they are using. I also have no experience with Linux or BSD, I'm ok on DOS though, so its more a matter of just not knowing any of the commands.
Stupidly, I replicated it right to the top level of the 2nd pool, which is probably a large part of why I'm struggling here.
At this point, even if I could restore the old pool and copy the data off the very vey very slow way I would be fine with it.
Thanks for taking the to time to read all this, and especially if you have any suggestions to help.