Hi there, yesterday I replaced a 4tb drive with a 10tb drive, resilvering finished this morning.
Replacement was made just to enlarge the pool, nothing wrong with the 4tb drive.
Now i'm getting errors and server is resilvering again.
It started just about when I started to make a new jail, no idea if that's related.
Got this email
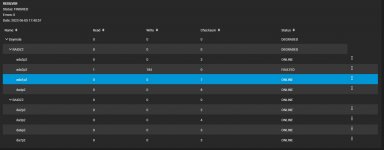
Then I checked the pool
Then again few min later I got another email.
Is this normal behaviour or is something wrong?
Replacement was made just to enlarge the pool, nothing wrong with the 4tb drive.
Now i'm getting errors and server is resilvering again.
It started just about when I started to make a new jail, no idea if that's related.
Got this email
Then few min laters I got another one.New alerts:
* Pool Geymsla state is ONLINE: One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected.
And another oneNew alert:
* Pool Geymsla state is ONLINE: One or more devices is currently being resilvered. The pool will continue to function, possibly in a degraded state.
The following alert has been cleared:
* Pool Geymsla state is ONLINE: One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected.
The following alert has been cleared:
* Pool Geymsla state is ONLINE: One or more devices is currently being resilvered. The pool will continue to function, possibly in a degraded state.
Then I checked the pool
Code:
root@freenas[~]# zpool status
pool: Geymsla
state: ONLINE
scan: resilvered 246M in 00:01:13 with 0 errors on Sun Jun 5 15:55:05 2022
config:
NAME STATE READ WRITE CKS UM
Geymsla ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gptid/55f18eb0-0700-11ea-b671-001e67b6be28 ONLINE 0 0 0
gptid/578d774b-0700-11ea-b671-001e67b6be28 ONLINE 0 0 0
gptid/5958c7a3-0700-11ea-b671-001e67b6be28 ONLINE 0 0 0
gptid/5b67112d-0700-11ea-b671-001e67b6be28 ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
gptid/c32349aa-e437-11ec-b872-001e67b6be28 ONLINE 0 0 0
gptid/e367f52b-0bb3-11ea-81da-001e67b6be28 ONLINE 0 0 0
gptid/e5c76fa6-0bb3-11ea-81da-001e67b6be28 ONLINE 0 0 0
gptid/e7ed145d-0bb3-11ea-81da-001e67b6be28 ONLINE 0 0 0
errors: No known data errors
Then again few min later I got another email.
And a follow up email a minute laterNew alerts:
* Pool Geymsla state is ONLINE: One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected.
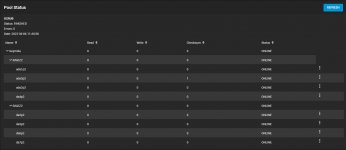
And I checked the pool again.The following alert has been cleared:
* Pool Geymsla state is ONLINE: One or more devices has experienced an unrecoverable error. An attempt was made to correct the error. Applications are unaffected.
Code:
root@freenas[~]# zpool status
pool: Geymsla
state: ONLINE
scan: resilvered 10.6M in 00:00:04 with 0 errors on Sun Jun 5 16:08:18 2022
config:
NAME STATE READ WRITE CKSUM
Geymsla ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gptid/55f18eb0-0700-11ea-b671-001e67b6be28 ONLINE 0 0 0
gptid/578d774b-0700-11ea-b671-001e67b6be28 ONLINE 0 0 0
gptid/5958c7a3-0700-11ea-b671-001e67b6be28 ONLINE 0 0 0
gptid/5b67112d-0700-11ea-b671-001e67b6be28 ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
gptid/c32349aa-e437-11ec-b872-001e67b6be28 ONLINE 0 0 0
gptid/e367f52b-0bb3-11ea-81da-001e67b6be28 ONLINE 0 0 0
gptid/e5c76fa6-0bb3-11ea-81da-001e67b6be28 ONLINE 0 0 0
gptid/e7ed145d-0bb3-11ea-81da-001e67b6be28 ONLINE 0 0 0
errors: No known data errors
Is this normal behaviour or is something wrong?