Aiming to mostly replicate the build from @Stux (with some mods, hopefully around about as good as that
link)
- 4 xSamsung 850 EVO Basic (500GB, 2.5") - - VMs/Jails
- 1 xASUS Z10PA-D8 (LGA 2011-v3, Intel C612 PCH, ATX) - - Dual socket MoBo
2 xWD Green 3D NAND (120GB, 2.5") - - Boot drives (maybe mess around trying out the thread to put swap here too link)- 1 x Kingston UV400 120GB SSD - boot drive (hit the 3D NAND/TRIM bug with the original WD green selection, failing scrub and showing as corrupted OS files) Decided to go with no mirror and use the config backup script
- 2 xIntel Xeon E5-2620 v4 (LGA 2011-v3, 2.10GHz) - - 8 core/16 threads per Chip
- 2 xNoctua NH-U9S (12.50cm)
- 1 xCorsair HX1200 (1200W) - PSU to support 24 HDD + several SSD and PCI cards
- 4 xKingston Value RAM (32GB, DDR4-2400, ECC RDIMM 288)
- 2 xNoctua NF-A8 PWM Premium 80mm PC Computer Case Fan
3 xNoctua NF-F12 PWM Cooling Fan- 3 xNoctua NF-F12 PPC 3000 PWM (120mm) * having noted later in Stux's thread that 1500 RPM is not sufficient to cool the HDDs. Corsair Commander Pro to control the fans (see script and code)
- 1 xNORCO 4U Rack Mount 24 x Hot-Swappable SATA/SAS 6G Drive Bays Server Rack mount RPC-4224
- 6 xCableCreation Internal Mini SAS HD Cable, Mini SAS SFF-8643 to Mini SAS 36Pin SFF-8087 Cable
- 1 xLSI Logic Controller Card 05-25699-00 9305-24i 24-Port SAS 12Gb/s PCI-Express 3.0 Host Bus Adapter
- TrueNAS Core 13.0-U6.1
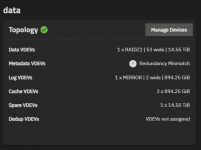
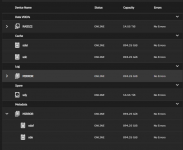
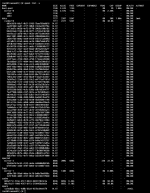
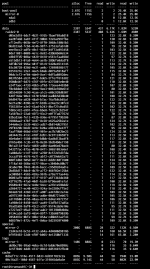
- Use existing Drives 8 x10TB WD Red, 8 x4TB WD Purple, + a mix of WD Purple and shucked WD Elements 12TB x 8
ESXi-pfSense-TrueNAS-Docker host
CASE: Fractal Node 804
MB: ASUS x-99M WS
CPU: Xeon E5-2620v4 + Corsair H60 Cooler block
RAM: CRUCIAL 64GB DDR4-2133 ECC RDIMMs
HDD: WD RED 3TBx8
SSD: 4 x
Samsung 850 EVO Basic (500GB, 2.5") - - VMs/Jails
HBA: LSI 9300-16i
OS: 1 x Kingston UV400 120GB SSD - boot drive
PSU: Corsair RM1000
Version: TrueNAS CORE 13.0 -U6.1
FANS: 3xFractal R3 120mm - 3 Front, 1 Rear. Corsair Commander Pro to control the fans (see
script and code)
CPU FAN: 1xCorsair H60 CPU Radiator - Front
NIC: Intel EXPI9402PTBLK Pro, Dual-Gigabit Adapter (plus the 2 onboard Intel NICs, 1x 210, 1x 218)
VM/Docker host, using ESXi and running pfSense alongside FreeNAS (separate Dual Intel NIC added, dedicated to the pfSense VM)
Other Systems
TrueNAS CORE test system:
CASE: Old Silverstone HTPC case
MB: ASUS x-99M WS
CPU: Xeon E5-2620v4 + Corsair H60 Cooler block
RAM: CRUCIAL 32GB DDR4-2133 ECC RDIMMs
HDD: WD RED 8TBx3
OS: 1 x Kingston UV400 120GB SSD - boot drive
PSU: Corsair RM1000
Version: TrueNAS CORE 13.0-U6.1
SCALE Cluster:
2x Intel NUCs running TrueNAS SCALE 24.04-BETA1
64GB RAM
10th Generation Intel i7
Samsung NVME SSD 1TB, QVO SSD 1TB
Boot from Samsung Portable T7 SSD USBC
CASE: Fractal Define 7 running TrueNAS SCALE 24.04-BETA1
MB: ASUS P10S-I Series
RAM: 32 GB
CPU: Intel(R) Xeon(R) CPU E3-1240L v5 @ 2.10GHz
HDD: 3 WD REDs and a few SSDs
PSU: Fractal ION 2+ 650W