Hello,
I am setting up a new home server with Scale. This is my first dealing with TrueNAS (coming from ProxmoxVE).
I'm just a hobbyist so I tend to get in over my head on some of this. I have an issue and I'm not sure if it is a problem or not. Also, if it is a problem, how can I resolve it?
Details below.
I have a fairly simple server based on a Supermicro X10SRH-CF (built in SAS3008), 64GB of Reg ECC and a pool of 5x HGST HE10 8TB drives (retired from enterprise service) and a few SSDs to run containers/apps. I have Scale 11.12.0 installed successfully and I've been trying to make sure the "new to me" 8TB drives are up to the task. I started by putting them all through a SMART Long test using the TrueNAS Storage GUI.
I made the initial mistake of not selecting all 5 drives and was doing them individually. I initially saw some error messages about only being able to run one at a time? At some point shortly after that, I realized that I should have selected all 5 drives and then initiated the SMART Long test.
So long story short, I have done several power on/off cycles, I did get one full run of SMART Long tests (simultaneous 5 drives) to run successfully, but oddly, both TrueNAS and Putty's smartctl show all 5 drives are still running a long test, but there is nothing showing in the jobs tab. This has been several days now. The Running test pre-dates the successful tests.
Here is an example of what comes up for SDA:
root@truenas[~]# smartctl -a /dev/sda
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.15.79+truenas] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Vendor: HGST
Product: HUH721008AL5200
Revision: A384
Compliance: SPC-4
User Capacity: 8,001,563,222,016 bytes [8.00 TB]
Logical block size: 512 bytes
Physical block size: 4096 bytes
LU is fully provisioned
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Logical Unit id: 0x5000cca2520beba0
Serial number: 7SG6K74C
Device type: disk
Transport protocol: SAS (SPL-3)
Local Time is: Sat Jan 21 11:46:51 2023 EST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Temperature Warning: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Health Status: OK
Grown defects during certification <not available>
Total blocks reassigned during format <not available>
Total new blocks reassigned <not available>
Power on minutes since format <not available>
Current Drive Temperature: 28 C
Drive Trip Temperature: 85 C
Accumulated power on time, hours:minutes 38718:40
Manufactured in week 12 of year 2017
Specified cycle count over device lifetime: 50000
Accumulated start-stop cycles: 95
Specified load-unload count over device lifetime: 600000
Accumulated load-unload cycles: 1583
Elements in grown defect list: 0
Vendor (Seagate Cache) information
Blocks sent to initiator = 22030695324975104
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 4463 0 4463 73165473 209169.321 0
write: 0 0 0 0 4775605 183118.763 0
verify: 0 2013 0 2013 3100719 341980.772 0
Non-medium error count: 0
SMART Self-test log
Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ]
Description number (hours)
# 1 Background long Completed - 38684 - [- - -]
# 2 Background long Self test in progress ... - NOW - [- - -]
# 3 Background short Completed - 38647 - [- - -]
# 4 Background short Completed - 38623 - [- - -]
# 5 Background short Completed - 38599 - [- - -]
# 6 Background short Completed - 38575 - [- - -]
# 7 Background short Completed - 38556 - [- - -]
Long (extended) Self-test duration: 60592 seconds [1009.9 minutes]
root@truenas[~]#
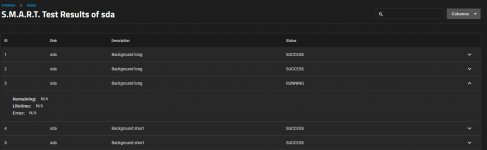
In addition, all of the drives look like this in the Storage GUI:

I don't understand why a complete power down doesn't clear these background long tests.
Is this something I should worry about or is it just a glitch that I shouldn't worry about? I haven't started the more strenuous BadBlock testing or any migration.
Thanks for any help.
I am setting up a new home server with Scale. This is my first dealing with TrueNAS (coming from ProxmoxVE).
I'm just a hobbyist so I tend to get in over my head on some of this. I have an issue and I'm not sure if it is a problem or not. Also, if it is a problem, how can I resolve it?
Details below.
I have a fairly simple server based on a Supermicro X10SRH-CF (built in SAS3008), 64GB of Reg ECC and a pool of 5x HGST HE10 8TB drives (retired from enterprise service) and a few SSDs to run containers/apps. I have Scale 11.12.0 installed successfully and I've been trying to make sure the "new to me" 8TB drives are up to the task. I started by putting them all through a SMART Long test using the TrueNAS Storage GUI.
I made the initial mistake of not selecting all 5 drives and was doing them individually. I initially saw some error messages about only being able to run one at a time? At some point shortly after that, I realized that I should have selected all 5 drives and then initiated the SMART Long test.
So long story short, I have done several power on/off cycles, I did get one full run of SMART Long tests (simultaneous 5 drives) to run successfully, but oddly, both TrueNAS and Putty's smartctl show all 5 drives are still running a long test, but there is nothing showing in the jobs tab. This has been several days now. The Running test pre-dates the successful tests.
Here is an example of what comes up for SDA:
root@truenas[~]# smartctl -a /dev/sda
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.15.79+truenas] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Vendor: HGST
Product: HUH721008AL5200
Revision: A384
Compliance: SPC-4
User Capacity: 8,001,563,222,016 bytes [8.00 TB]
Logical block size: 512 bytes
Physical block size: 4096 bytes
LU is fully provisioned
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Logical Unit id: 0x5000cca2520beba0
Serial number: 7SG6K74C
Device type: disk
Transport protocol: SAS (SPL-3)
Local Time is: Sat Jan 21 11:46:51 2023 EST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Temperature Warning: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Health Status: OK
Grown defects during certification <not available>
Total blocks reassigned during format <not available>
Total new blocks reassigned <not available>
Power on minutes since format <not available>
Current Drive Temperature: 28 C
Drive Trip Temperature: 85 C
Accumulated power on time, hours:minutes 38718:40
Manufactured in week 12 of year 2017
Specified cycle count over device lifetime: 50000
Accumulated start-stop cycles: 95
Specified load-unload count over device lifetime: 600000
Accumulated load-unload cycles: 1583
Elements in grown defect list: 0
Vendor (Seagate Cache) information
Blocks sent to initiator = 22030695324975104
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 4463 0 4463 73165473 209169.321 0
write: 0 0 0 0 4775605 183118.763 0
verify: 0 2013 0 2013 3100719 341980.772 0
Non-medium error count: 0
SMART Self-test log
Num Test Status segment LifeTime LBA_first_err [SK ASC ASQ]
Description number (hours)
# 1 Background long Completed - 38684 - [- - -]
# 2 Background long Self test in progress ... - NOW - [- - -]
# 3 Background short Completed - 38647 - [- - -]
# 4 Background short Completed - 38623 - [- - -]
# 5 Background short Completed - 38599 - [- - -]
# 6 Background short Completed - 38575 - [- - -]
# 7 Background short Completed - 38556 - [- - -]
Long (extended) Self-test duration: 60592 seconds [1009.9 minutes]
root@truenas[~]#
In addition, all of the drives look like this in the Storage GUI:
I don't understand why a complete power down doesn't clear these background long tests.
Is this something I should worry about or is it just a glitch that I shouldn't worry about? I haven't started the more strenuous BadBlock testing or any migration.
Thanks for any help.