jakehansen
Cadet
- Joined
- Mar 28, 2020
- Messages
- 3
First and foremost, I want to say the standard "long time lurker, first time poster". Considering this, I understand from my experience with the forum how important it is to do your homework and research, research, research before you post anything. I feel as if I have done my due diligence as I have researched the question that I have extensively and have learned a lot, but have not come to a conclusive answer/solution. I appreciate any help and am well aware I have quite a few things I probably need to learn, but I am open to learning.
With that in mind, here goes.
I currently am running FreeNAS on a Dell Poweredge R420 (specs below) and I access it via iSCSI from an ESXi machine (the ESXi machine is the only initiator). For disks, I have 4 7200 RPM SAS 2TB drives configured as mirrored VDEVs in one pool. Currently, I have no L2ARC or SLOG (this is part of my question to come). My iSCSI zvol is configured at 50% capacity of the entire pool, to help performance because of fragmentation. Currently, my fragmentation is at 0% since I have erased my pool and started over to try to solve this problem.
This setup has worked great for me for about a year. On the ESXi box, I have one datastore residing on the presented iSCSI drive, and my VMs use that datastore solely for file storage. The boot volumes for the VMs are on a separate, SSD backed RAID. I was consistently maxing out a gigabit connection on both sequential reads and writes on my VMs. Now, I recently upgraded my ESXi host and FreeNAS box to 10Gb. The ESXi host and FreeNAS box are connected directly to each other via the 10Gb nics. The problem I see now is my writes are stuck around 110 MB/s, but reads are fine as they are maxing out the 10g connection. Below, I'll provide all the troubleshooting I have done.
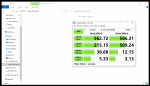
First, it's helpful to know the maximum write speed of my pool. I setup a test datastore with compression disabled in order to run a quick dd test on the FreeNAS box. My results show around 220 - 250 MB/s when copying a 20 GB file with 1024k block size. This is performance I expect for my mirrored VDEVs.
Next, I made sure I tested the 10Gb connection between my FreeNAS box and ESXi box using iPerf3. This test showed I was sustaining a connection of around 9.41 Gbps. Exactly the performance I expect.
Next, I tested the performance of the datastore I created on the presented iSCSI volume by running dd on the datastore from the ESXi box. Here, I get around 110 MB/s. So at least I know there isn't an issue between any of the VMs and the datastore since the problem shows up when writing directly to the datastore from ESXi.
Since I researched this problem a ton, I decided to adjust a few different settings but none of them helped. First, I followed the iSCSI best practice guide for FreeNAS (can't remember the link, but if you search for it you can find it). I tried jumbo frames, making sure the vSwitch and the nics all are set at 9000 mtu. I tried disabling delay ACK. Tried a few different tunables. Nothing was helping.
Just to keep my sanity, I created an SMB share on the same pool as the iSCSI zvol and connected to it via one of my VMs. There, I was getting around 220 - 250 MB/s sequential write. So, I know my network and storage array are capable of these speeds.
Just for fun, I tried reconfiguring my pool to stripe just two disks together and present that over iSCSI. When doing this, I now got 220 - 250 MB/s! Now I'm really confused.
As a side note, no matter what protocol I use (iSCSI or SMB) and no matter what configuration I have my VDEVs in (2 mirrored VDEVs or 2 stripped disks), my sequential writes always start out around 900 MB/s, saturating my 10Gb connection. This speed only lasts for a couple of seconds, obviously, since this speed is due to FreeNAS's cache, but it further proves that my network and the protocols I am choosing are capable of the speeds I am expecting.
I've read all the posts about iSCSI and really focused on jgreco's responses and those posts were helpful. I even tried resetting my expectations about what performance I can get out of my current hardware. The thing that is bothering me is that I know my array and network are capable of the speeds I am expecting, but iSCSI is posing some sort of problem (it seems). What really bothers me is that I'm getting the speeds I am expecting over iSCSI when two disks are stripped, just not on a pool of mirrored VDEVs between all 4 of my disks.
To me, it seems like my mirrored VDEVs are causing some sort of problem over iSCSI, since I get the expected performance out of 2, stripped disks over iSCSI. Unfortunately, I just don't know what that problem is.
I stated earlier that I know I might need a SLOG and potentially L2ARC. From reading about what SLOG improves for iSCSI, I'm struggling to understand how it will help me in my situation. From what I've read, it seems that SLOG is only useful in an iSCSI configuration if sync writes are being used. In my case, I'm not using sync writes, so I don't think SLOG would help me. Currently, I'm satisfied with my read speeds, so I'm not sure that I'm ready to add L2ARC.
In the coming weeks, however, I plan on getting more RAM as I'd like to bump it up to at least 64GB. I don't think my RAM is my limitation right now, since I can get 200 - 250 MB/s sustained sequential writes in some configurations, as stated above.
Any direction would be appreciated!
Specs for FreeNAS box:
With that in mind, here goes.
I currently am running FreeNAS on a Dell Poweredge R420 (specs below) and I access it via iSCSI from an ESXi machine (the ESXi machine is the only initiator). For disks, I have 4 7200 RPM SAS 2TB drives configured as mirrored VDEVs in one pool. Currently, I have no L2ARC or SLOG (this is part of my question to come). My iSCSI zvol is configured at 50% capacity of the entire pool, to help performance because of fragmentation. Currently, my fragmentation is at 0% since I have erased my pool and started over to try to solve this problem.
This setup has worked great for me for about a year. On the ESXi box, I have one datastore residing on the presented iSCSI drive, and my VMs use that datastore solely for file storage. The boot volumes for the VMs are on a separate, SSD backed RAID. I was consistently maxing out a gigabit connection on both sequential reads and writes on my VMs. Now, I recently upgraded my ESXi host and FreeNAS box to 10Gb. The ESXi host and FreeNAS box are connected directly to each other via the 10Gb nics. The problem I see now is my writes are stuck around 110 MB/s, but reads are fine as they are maxing out the 10g connection. Below, I'll provide all the troubleshooting I have done.
First, it's helpful to know the maximum write speed of my pool. I setup a test datastore with compression disabled in order to run a quick dd test on the FreeNAS box. My results show around 220 - 250 MB/s when copying a 20 GB file with 1024k block size. This is performance I expect for my mirrored VDEVs.
Next, I made sure I tested the 10Gb connection between my FreeNAS box and ESXi box using iPerf3. This test showed I was sustaining a connection of around 9.41 Gbps. Exactly the performance I expect.
Next, I tested the performance of the datastore I created on the presented iSCSI volume by running dd on the datastore from the ESXi box. Here, I get around 110 MB/s. So at least I know there isn't an issue between any of the VMs and the datastore since the problem shows up when writing directly to the datastore from ESXi.
Since I researched this problem a ton, I decided to adjust a few different settings but none of them helped. First, I followed the iSCSI best practice guide for FreeNAS (can't remember the link, but if you search for it you can find it). I tried jumbo frames, making sure the vSwitch and the nics all are set at 9000 mtu. I tried disabling delay ACK. Tried a few different tunables. Nothing was helping.
Just to keep my sanity, I created an SMB share on the same pool as the iSCSI zvol and connected to it via one of my VMs. There, I was getting around 220 - 250 MB/s sequential write. So, I know my network and storage array are capable of these speeds.
Just for fun, I tried reconfiguring my pool to stripe just two disks together and present that over iSCSI. When doing this, I now got 220 - 250 MB/s! Now I'm really confused.
As a side note, no matter what protocol I use (iSCSI or SMB) and no matter what configuration I have my VDEVs in (2 mirrored VDEVs or 2 stripped disks), my sequential writes always start out around 900 MB/s, saturating my 10Gb connection. This speed only lasts for a couple of seconds, obviously, since this speed is due to FreeNAS's cache, but it further proves that my network and the protocols I am choosing are capable of the speeds I am expecting.
I've read all the posts about iSCSI and really focused on jgreco's responses and those posts were helpful. I even tried resetting my expectations about what performance I can get out of my current hardware. The thing that is bothering me is that I know my array and network are capable of the speeds I am expecting, but iSCSI is posing some sort of problem (it seems). What really bothers me is that I'm getting the speeds I am expecting over iSCSI when two disks are stripped, just not on a pool of mirrored VDEVs between all 4 of my disks.
To me, it seems like my mirrored VDEVs are causing some sort of problem over iSCSI, since I get the expected performance out of 2, stripped disks over iSCSI. Unfortunately, I just don't know what that problem is.
I stated earlier that I know I might need a SLOG and potentially L2ARC. From reading about what SLOG improves for iSCSI, I'm struggling to understand how it will help me in my situation. From what I've read, it seems that SLOG is only useful in an iSCSI configuration if sync writes are being used. In my case, I'm not using sync writes, so I don't think SLOG would help me. Currently, I'm satisfied with my read speeds, so I'm not sure that I'm ready to add L2ARC.
In the coming weeks, however, I plan on getting more RAM as I'd like to bump it up to at least 64GB. I don't think my RAM is my limitation right now, since I can get 200 - 250 MB/s sustained sequential writes in some configurations, as stated above.
Any direction would be appreciated!
Specs for FreeNAS box:
- Motherboard: Whatever motherboard comes with the R420
- Processors: 2 x 6 core 2.20 Ghz E5-2430
- RAM: 24 GB DDR3 ECC RAM
- Disks: 4 x Seagate ES.3 Constellation 2TB SAS
- HBA: Dell H310 Mini flashed to IT mode (LSI 9211-8i)
- NIC: Broadcom 57810S