nickwebha
Dabbler
- Joined
- Sep 15, 2017
- Messages
- 12
[Jump down to post #15 to see the most updated information.]
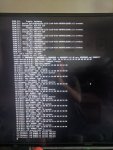
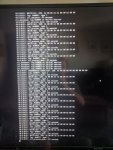
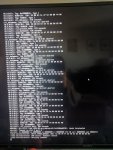
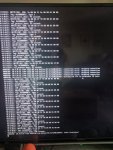
I have been running FreeNAS for a few years now (since 9.x?). Same hardware, never had a problem besides a boot device dying here or there. Now the machine is rebooting every few days. As you can imagine iSCSI is not a fan to say the least.
I assume this is a kernel panic but am unsure on FreeBSD how to check that. What logs do I need to look at to see why the thing is rebooting on its own?
Thanks.
- FreeNAS version
- 11.3
- Motherboard make and model
- ASRock C2750D4I
- CPU make and model
- Intel Octa Core Avoton C2750 Processor
- RAM quantity
- 32GB
- Hard drives, quantity, model numbers, and RAID configuration, including boot drives
- 12
- Seagate ST6000DX000
- raidz3
- Dual Samsung Fit Plus 32GB
- Hard disk controllers
- Intel® C2750 : 2 x SATA3 6.0 Gb/s, 4 x SATA2 3.0 Gb/s
- Marvell SE9172: 2 x SATA3 6.0 Gb/s
- Marvell SE9230: 4 x SATA3 6.0 Gb/s
- Network cards
- [Built-in/unknown] Dual gigabit
I have been running FreeNAS for a few years now (since 9.x?). Same hardware, never had a problem besides a boot device dying here or there. Now the machine is rebooting every few days. As you can imagine iSCSI is not a fan to say the least.
I assume this is a kernel panic but am unsure on FreeBSD how to check that. What logs do I need to look at to see why the thing is rebooting on its own?
Thanks.
Last edited: