I'm preparing to move a series of datasets residing on one encrypted pool to another pool. This is primarily intended to be a move from a smaller pool of storage to a larger pool of storage, after which point I'll destroy the smaller pool.
The source pool, tank, is set up with TrueNAS 12.0-R ZFS native encryption, not GELI. Most child datasets inherit that encryption, though a couple have their own passphrase-based encryption.
It is my desire to have ALL of my data encrypted, and to NEVER have unencrypted data touch a storage medium. This is in part so that RMAs of drives, should that be necessary, are not a potential source of data leakage.
The destination pool, dozer, was also set up with ZFS native encryption, with its own key.
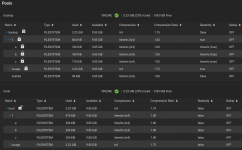
When I set up a replication task to send the entire pool tank and everything within it to dozer, it fails: "Destination dataset 'dozer' already exists and is it's own encryption root. This configuration is not supported yet. If you want to replicate into an encrypted dataset, please, encrypt it's parent dataset."
OK, fair enough. For the purposes of testing, I created a new dataset on dozer that inherits dozer's encryption, and copied some inconsequential files to that dataset.
I then created another new pool, frank, with no encryption. I then set up a replication task to send all of pool dozer to pool frank.
This also failed:
Error
Unable to send encrypted dataset 'dozer' to existing unencrypted or unrelated dataset 'frank'.
Logs
[2020/12/27 19:46:27] INFO [replication_task__task_21] [zettarepl.replication.run] For replication task 'task_21': doing push from 'dozer' to 'frank' of snapshot='auto-2020-12-27_19-46' incremental_base=None receive_resume_token=None encryption=False
[2020/12/27 19:46:27] ERROR [replication_task__task_21] [zettarepl.replication.run] For task 'task_21' non-recoverable replication error ReplicationError("Unable to send encrypted dataset 'dozer' to existing unencrypted or unrelated dataset 'frank'")
I have been able to replicate individual datasets from one pool to another, but that just results in encrypted datasets sitting static on the destination pool. I really want a new pool where the encryption/decryption is handled transparently as with the original pool.
I'll be the first to admit that I don't fully understand replication, but it seems that I can't replicate an encrypted pool to a new pool. What am I missing?
The source pool, tank, is set up with TrueNAS 12.0-R ZFS native encryption, not GELI. Most child datasets inherit that encryption, though a couple have their own passphrase-based encryption.
It is my desire to have ALL of my data encrypted, and to NEVER have unencrypted data touch a storage medium. This is in part so that RMAs of drives, should that be necessary, are not a potential source of data leakage.
The destination pool, dozer, was also set up with ZFS native encryption, with its own key.
When I set up a replication task to send the entire pool tank and everything within it to dozer, it fails: "Destination dataset 'dozer' already exists and is it's own encryption root. This configuration is not supported yet. If you want to replicate into an encrypted dataset, please, encrypt it's parent dataset."
OK, fair enough. For the purposes of testing, I created a new dataset on dozer that inherits dozer's encryption, and copied some inconsequential files to that dataset.
I then created another new pool, frank, with no encryption. I then set up a replication task to send all of pool dozer to pool frank.
This also failed:
Error
Unable to send encrypted dataset 'dozer' to existing unencrypted or unrelated dataset 'frank'.
Logs
[2020/12/27 19:46:27] INFO [replication_task__task_21] [zettarepl.replication.run] For replication task 'task_21': doing push from 'dozer' to 'frank' of snapshot='auto-2020-12-27_19-46' incremental_base=None receive_resume_token=None encryption=False
[2020/12/27 19:46:27] ERROR [replication_task__task_21] [zettarepl.replication.run] For task 'task_21' non-recoverable replication error ReplicationError("Unable to send encrypted dataset 'dozer' to existing unencrypted or unrelated dataset 'frank'")
I have been able to replicate individual datasets from one pool to another, but that just results in encrypted datasets sitting static on the destination pool. I really want a new pool where the encryption/decryption is handled transparently as with the original pool.
I'll be the first to admit that I don't fully understand replication, but it seems that I can't replicate an encrypted pool to a new pool. What am I missing?
 The same issue technically concerns the first-time creation of iocage for your jails.
The same issue technically concerns the first-time creation of iocage for your jails.