dgarner-cg
Dabbler
- Joined
- Sep 26, 2023
- Messages
- 11
Good afternoon, everyone.
I know this has been posted a million times here, so through my use of search function, I will attempt to give all details needed to prevent redundant questions having to be asked..
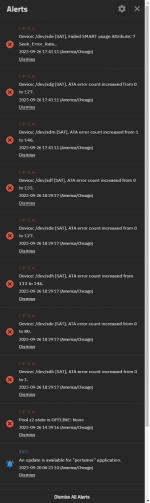
Today, after attempting to update my HPE server firmware running my NAS, my pool has died.
I am running z2.
This pool initially was 8 active drives with 4 (FOUR) hot spares ... so I'm somewhat at a loss for how this has so many catastrophic failures at the exact same time...
When I visit the GUI, the only thing I can find about the pool is it being showed as exported under Storage > Disks..

It is not available under storage > import pool although it's recognized in several places as being part of z2..

in console,
$z2 status
$z2 import
Any and all help would be unbelievable .. This is fairly mission critical, hence the 4 hot spares that apparently were 100% all part of a bad batch or something is really goofed up here..
I know this has been posted a million times here, so through my use of search function, I will attempt to give all details needed to prevent redundant questions having to be asked..
Today, after attempting to update my HPE server firmware running my NAS, my pool has died.
I am running z2.
This pool initially was 8 active drives with 4 (FOUR) hot spares ... so I'm somewhat at a loss for how this has so many catastrophic failures at the exact same time...
When I visit the GUI, the only thing I can find about the pool is it being showed as exported under Storage > Disks..
It is not available under storage > import pool although it's recognized in several places as being part of z2..
in console,
$z2 status
Code:
pool: boot-pool
state: ONLINE
status: Some supported and requested features are not enabled on the pool.
The pool can still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(7) for details.
scan: scrub repaired 0B in 00:00:15 with 0 errors on Thu Sep 21 03:45:17 2023
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
sda3 ONLINE 0 0 0
errors: No known data errors
pool: system
state: ONLINE
scan: scrub repaired 0B in 00:00:36 with 0 errors on Sun Sep 10 00:00:38 2023
config:
NAME STATE READ WRITE CKSUM
system ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
80e5349f-da1e-4e77-a6d8-a8c2c1ce76a9 ONLINE 0 0 0
b66c7018-9097-454b-89d9-4d638ffb2e85 ONLINE 0 0 0
errors: No known data errors$z2 import
Code:
pool: z2
id: 1052080854075599518
state: ONLINE
action: The pool can be imported using its name or numeric identifier.
config:
z2 ONLINE
raidz2-0 ONLINE
spare-0 ONLINE
74bbd376-271a-4e0d-89c5-13da850eee79 ONLINE
b451bd60-074b-4110-8845-800db5fa85b9 ONLINE
07c5606f-2055-4bc1-a5e1-f54387968d16 ONLINE
ab6bedd7-601e-4623-be42-50869b0ca6ed ONLINE
8106fd95-8e65-4f64-a5ea-8ce4a451c577 ONLINE
spares
b451bd60-074b-4110-8845-800db5fa85b9Any and all help would be unbelievable .. This is fairly mission critical, hence the 4 hot spares that apparently were 100% all part of a bad batch or something is really goofed up here..