Morpheus187
Explorer
- Joined
- Mar 11, 2016
- Messages
- 61
Hello
System board: Supermicro X11SSH-CTF-O
Ram: 64 GB ECC
CPU: E3-1245v5
16x8 TB HDD
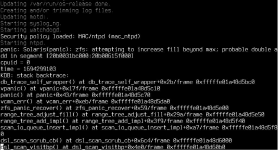
After physically moving a system it has crashes once and I observed Uncorrectable ECC errors in the IPMI
What seems strange is that dmesg or any other tool on the server doesn't show any error, it behaves absolutely normal. Also zpool status shows NO read errors or write errors.
But when I copy a large file to the system and copy it back, the checksum is always wrong, so it corrupts everything it gets.
I've now ran a scrub .. No just a joke. I shut down the system now and will investigate the issue and re-seat ram to see if that fixes the issue
Luckily the system is only a secondary system.
I just think it's a bit strange that it doesn't show any signs of a data corruption.
I can download a large file from Truenas 5 times and 5 times I get a file with a completely different md5 hash. But when I do file operations on Truenas itself without copying it over network, the hash stays the same. It seems that the memory error is mainly located in a area that is used for network transfer / samba as it toasts every file that is being transfered over network. The ZFS subsystem doesn't seem to be affected right now.
I thought I just share my findings because it's pretty rare to actually have an Uncorrectable ECC error with ECC ram.
UPDATE: Memtest agrees

System board: Supermicro X11SSH-CTF-O
Ram: 64 GB ECC
CPU: E3-1245v5
16x8 TB HDD
After physically moving a system it has crashes once and I observed Uncorrectable ECC errors in the IPMI
492 2023/08/11 22:35:17 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion 493 2023/08/11 22:35:17 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion 494 2023/08/11 22:35:17 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion 495 2023/08/11 22:35:18 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion 496 2023/08/11 22:35:18 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion 497 2023/08/11 22:35:18 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion 498 2023/08/11 22:35:18 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion 499 2023/08/11 22:35:18 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion 500 2023/08/11 22:35:18 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion 501 2023/08/11 22:35:19 OEM Memory Uncorrectable ECC @ DIMMB1 - Assertion
Code:
zpool status
pool: TANK
state: ONLINE
status: Some supported and requested features are not enabled on the pool.
The pool can still be used, but some features are unavailable.
action: Enable all features using 'zpool upgrade'. Once this is done,
the pool may no longer be accessible by software that does not support
the features. See zpool-features(7) for details.
scan: scrub repaired 0B in 11:42:52 with 0 errors on Sun Jul 23 11:42:53 2023
config:
NAME STATE READ WRITE CKSUM
TANK ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
gptid/3bfa2165-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/4423cee1-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/4c3bf716-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/54809430-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/5c9b9aa0-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/64ba6a24-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/75c846ed-40e4-11ea-bf7c-ac1f6b6ab88e ONLINE 0 0 0
gptid/751465c9-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
gptid/7d5bcb86-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/859ae1b4-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/8de09aa6-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/961d1a78-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/9e44d8a3-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/a670711d-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/aeac39ab-7ff9-11e9-adcd-ac1f6b6ab88e ONLINE 0 0 0
gptid/4a859d1e-f16c-11e9-9f4e-ac1f6b6ab88e ONLINE 0 0 0
errors: No known data errors
What seems strange is that dmesg or any other tool on the server doesn't show any error, it behaves absolutely normal. Also zpool status shows NO read errors or write errors.
But when I copy a large file to the system and copy it back, the checksum is always wrong, so it corrupts everything it gets.
I've now ran a scrub .. No just a joke. I shut down the system now and will investigate the issue and re-seat ram to see if that fixes the issue
Luckily the system is only a secondary system.
I just think it's a bit strange that it doesn't show any signs of a data corruption.
I can download a large file from Truenas 5 times and 5 times I get a file with a completely different md5 hash. But when I do file operations on Truenas itself without copying it over network, the hash stays the same. It seems that the memory error is mainly located in a area that is used for network transfer / samba as it toasts every file that is being transfered over network. The ZFS subsystem doesn't seem to be affected right now.
I thought I just share my findings because it's pretty rare to actually have an Uncorrectable ECC error with ECC ram.
UPDATE: Memtest agrees
Last edited: