
jgreco
Resident Grinch
- Joined
- May 29, 2011
- Messages
- 18,680
I’m not thinking that. According to Freenas they say you can use 50% for iscsi and 80% for nfs, without any performance degradation. And you say Freenas /ixsystem is wrong… ok, have to read your materials then.
I think you're confused and maybe misunderstood something somewhere.
80% is commonly considered a fill percentage for normal ZFS pools used for general file storage. This is the point at which performance degradation starts to become more noticeable. It isn't a fixed number, some people think it's closer to 90%, etc.
Back in 2012-2013 I was already talking about this problem and was considered a bit heretical or insane by people unwilling to try to understand, and my rule of thumb at the time was actually 60%, not 50%. See for ex.
Out of the blue vmware esx + iscsi issues
What? Your thread title says "... + iscsi issues". But you're not having issues with iscsi? So why did you create the thread? I'm confused as all hell now. And your Q9300 doesn't do 32GB of RAM. 8GB max with socket 775. ;)
I later lowered it to 40-50%. So you might want to listen to what I'm saying, because I'm PROBABLY the indirect source for the 50% you did hear. I eventually prevailed upon Dru to make more accurate real world estimates of eventual steady state ZFS performance in the long term, which is what got put in the FreeNAS manual, and iX engineers have been referred to some of my discussions over the years because I've gone into some detail. You can find numerous past discussions by looking for the word "contiguous" by "jgreco" in the search box. Many of the results will discuss this at varying levels of complexity. This is a tough concept to wrap your head around, and I am committed to trying to help promote understanding of the issue.
So let me summarize for you.
This is not a protocol issue, though stuff like volblocksize is somewhat related. The general problem applies to both NFS and iSCSI. The specifics for each are slightly different.
Due to its tendency to write blocks from a transaction group to contiguous LBA's on disks, even if the blocks in the transaction groups were what we would normally consider to be random writes to random locations, this means that ZFS tends to write faster because it isn't ACTUALLY seeking to write stuff that would normally require seeks on UFS or EXT3.
The problem is that this causes severe fragmentation over time, and the question is where does the merry go round ride end. Fortunately our friends over at Delphix did a study of this, which is part of what convinced me I was wrong about the 60% and that it needed to be lower.
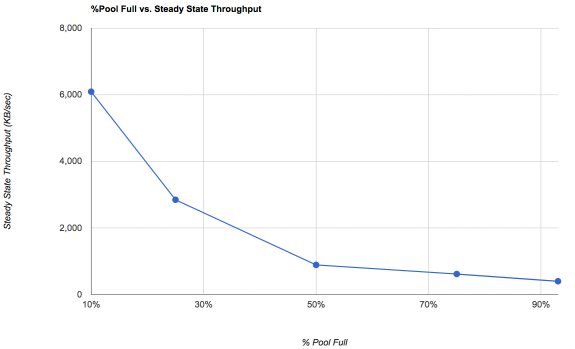
This table shows pool performance on a pool that is written to randomly until it achieves a stable throughput. This represents likely behaviour of your pool after extensive use and random overwrites. It's the number you can probably RELY on for your pool performance to never get worse than.
What this is saying is that at 10% pool capacity, your pool will be about 6x faster for writes than your pool at 50% capacity. The hard data presented here caused me to rethink the 60% advice I had been giving for years, because it's pretty clear that at 50% you're already into the "wow that sucks" area of the graph.
The problem is that most people don't do the hard work to figure out where things end up. They get a new pool that's empty and they do some benchmarks on it, and they think holy bitpools batman this is amazingly fast. The problem is that you need to understand how performance will evolve over time and what factors impact this. At 50%, you may actually be fine because most block storage usage does not cause maximal fragmentation, so YOUR steady state graph may not end up at the pessimistic low level. If you run VM's that do not frequently overwrite all their data, you will end up in a somewhat better curve, or that approach the pessimistic level over a much longer period of time -- years or even decades.
