
Hi,
Since updating from 11.3 to 12.0 I see strange RAM usage. Most of the time services are using 10-12 of 32GB RAM. But sometimes the services are going up to 30GB. It stays there for a while and after some hours it might go down to 10-12GB again. Then there is alot of free RAM because the ARC got shunk down to 1GB and over time the ARC is growing to 19-21 GB again.
What could cause this? I thought there might be a memery leak or something like that but with memory leaks the service size should stay high right?

This is the output of "top -o res" while services are using 29.6GiB:
So I can't see what should use that much RAM. The 3 bhye processes are my 3 VMs. They got 3GB+1GB+512MB RAM so that looks normal.
I'm running no jails and my enabled services are FTP, NFS, Rsync, SMART, SMB, SNMP, SSH and UPS. If I disable all services while services are maxing out the RAM it doens't lower the RAM usage.
I'm running TrueNAS Core 12.0U4.1 on a Supermicro X10SLL-F + 32GB ECC RAM + Xeon E3-1230v3.
Any ideas?
Edit:
"arc_summary" also shows me that the ARC is shrunken down to 1.6 GiB so that RAM usage is not just a widget display error. So what is eating all that RAM? Are there some commands other than "top" I can run to see what is using that RAM?
Edit:
Now its freed up again without me doing anything:

Top sorted by res:
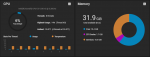
And diagrams:


Since updating from 11.3 to 12.0 I see strange RAM usage. Most of the time services are using 10-12 of 32GB RAM. But sometimes the services are going up to 30GB. It stays there for a while and after some hours it might go down to 10-12GB again. Then there is alot of free RAM because the ARC got shunk down to 1GB and over time the ARC is growing to 19-21 GB again.
What could cause this? I thought there might be a memery leak or something like that but with memory leaks the service size should stay high right?
This is the output of "top -o res" while services are using 29.6GiB:
Code:
last pid: 39792; load averages: 0.58, 0.49, 0.48 up 5+23:13:41 21:42:40
104 processes: 1 running, 103 sleeping
CPU: 1.8% user, 0.0% nice, 1.3% system, 0.1% interrupt, 96.8% idle
Mem: 626M Active, 6674M Inact, 980K Laundry, 23G Wired, 740M Free
ARC: 1626M Total, 418M MFU, 585M MRU, 15M Anon, 52M Header, 556M Other
297M Compressed, 967M Uncompressed, 3.25:1 Ratio
Swap: 6144M Total, 6144M Free
PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND
4380 root 45 20 0 3159M 1915M kqread 3 393:15 2.05% bhyve
4257 root 40 20 0 1087M 766M kqread 3 592:32 4.86% bhyve
369 root 45 23 0 620M 492M kqread 0 112:07 0.03% python3.9
2009 root 4 30 0 465M 453M select 5 457:40 0.00% python3.9
4625 root 1 20 0 481M 438M kqread 2 38:20 0.00% smbd
4352 root 29 20 0 561M 433M kqread 7 237:40 1.50% bhyve
85591 root 1 20 0 246M 217M kqread 2 0:00 0.00% smbd
16670 root 1 20 0 256M 216M kqread 4 87:43 0.00% smbd
87437 root 1 20 0 261M 214M kqread 6 55:38 0.00% smbd
35272 root 1 20 0 248M 209M kqread 0 0:25 0.00% smbd
35271 root 1 20 0 247M 208M kqread 4 0:01 0.00% smbd
35277 root 1 20 0 248M 208M kqread 6 0:01 0.00% smbd
35274 root 1 20 0 247M 208M kqread 0 0:01 0.00% smbd
35270 root 1 20 0 246M 207M kqread 4 0:00 0.00% smbd
35275 root 1 20 0 246M 207M kqread 3 0:01 0.00% smbdSo I can't see what should use that much RAM. The 3 bhye processes are my 3 VMs. They got 3GB+1GB+512MB RAM so that looks normal.
I'm running no jails and my enabled services are FTP, NFS, Rsync, SMART, SMB, SNMP, SSH and UPS. If I disable all services while services are maxing out the RAM it doens't lower the RAM usage.
I'm running TrueNAS Core 12.0U4.1 on a Supermicro X10SLL-F + 32GB ECC RAM + Xeon E3-1230v3.
Any ideas?
Edit:
"arc_summary" also shows me that the ARC is shrunken down to 1.6 GiB so that RAM usage is not just a widget display error. So what is eating all that RAM? Are there some commands other than "top" I can run to see what is using that RAM?
Edit:
Now its freed up again without me doing anything:
Top sorted by res:
Code:
last pid: 46223; load averages: 0.70, 0.53, 0.45 up 6+00:13:19 22:42:18
101 processes: 1 running, 100 sleeping
CPU: 1.3% user, 0.0% nice, 1.4% system, 0.1% interrupt, 97.2% idle
Mem: 648M Active, 6670M Inact, 968K Laundry, 4679M Wired, 19G Free
ARC: 1769M Total, 436M MFU, 707M MRU, 17M Anon, 53M Header, 557M Other
348M Compressed, 1044M Uncompressed, 2.99:1 Ratio
Swap: 6144M Total, 6144M Free
PID USERNAME THR PRI NICE SIZE RES STATE C TIME WCPU COMMAND
4380 root 45 20 0 3159M 1916M kqread 0 396:29 4.18% bhyve
4257 root 40 20 0 1087M 766M kqread 6 597:25 4.56% bhyve
369 root 42 20 0 654M 512M kqread 1 113:12 0.83% python3.9
2009 root 4 31 0 467M 455M select 4 460:58 0.39% python3.9
4625 root 1 20 0 482M 439M kqread 1 38:29 0.00% smbd
4352 root 29 20 0 561M 433M kqread 5 239:36 2.33% bhyve
16670 root 1 20 0 256M 218M kqread 1 87:44 0.00% smbd
85591 root 1 20 0 246M 218M kqread 4 0:00 0.00% smbd
87437 root 1 20 0 261M 214M kqread 2 55:38 0.00% smbd
35272 root 1 20 0 248M 209M kqread 0 0:25 0.00% smbd
35271 root 1 20 0 247M 208M kqread 4 0:01 0.00% smbd
35277 root 1 20 0 248M 208M kqread 7 0:01 0.00% smbd
35274 root 1 20 0 247M 208M kqread 2 0:01 0.00% smbd
35270 root 1 20 0 246M 207M kqread 3 0:00 0.00% smbd
35275 root 1 20 0 246M 207M kqread 5 0:01 0.00% smbd
And diagrams:
Attachments
Last edited: