schmidtd0039
Dabbler
- Joined
- Feb 6, 2024
- Messages
- 13
Hello All,
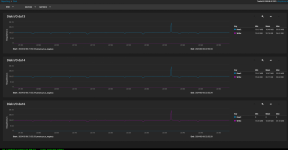
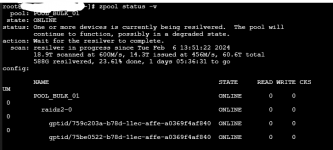
I'm hoping to get some help on a topic I know comes up frequently, but I'm having trouble understanding how is impacting my setup based on other online results. I had a drive failure today, and I'm in the process of resilvering the drive, but I'm seeing MAX 18MB/s writing to the new drive, and while my resilver percent is moving up for now, the time is only increasing, rather dramatically at that.
System Details:
TrueNAS-13.0-U4
Intel E5-1660 v3, 8C 16T
128GB DDR4 ECC
2x10GB Intel x520-DA2
x2 Toshiba 128GB SATA SSDs for Boot
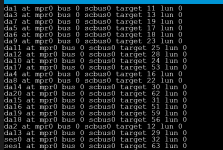
x16 HUH721010AL42C0 10TB SAS HDDs
(No cache, just spinners)
SuperMicro mobo X10SRH-CF
Supermicro 36 Bay Chassis; SAS-3 backplane, onboard raid card flashed to IT Mode
Pool #1
Encryption on
Sync Standard
no Compression, no DeDup
2 vDevs of 8 drives, each vDev is x8 10TB drives
100TB usable pool size, with 40TB in use and 60TB free
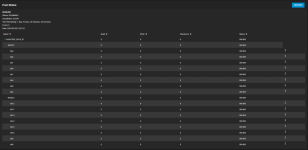
Recent smart tests, long and short, have all passed on all drives (except the bad one I swapped), shorts run daily and longs weekly. The last scrub job was timed poorly and unfortunately timed out due to the bad drive, and hasn't been ran in ~30 days. (plan to run once resilver catches up).
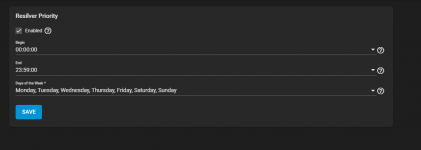
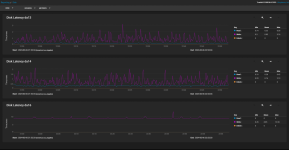
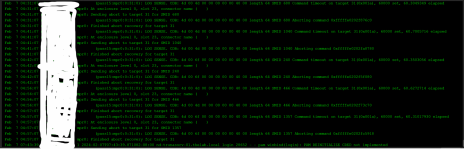
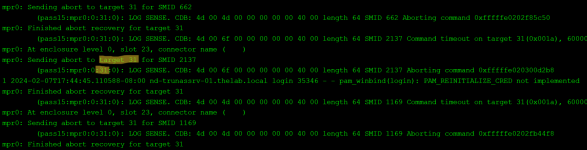
I also noticed I had never set a Resilver priority before this started, so I initially thought that was it. However, even after updating the priority to all-day, the speed hasn't changed and rests at 18MB/s consistently for the last 10 hours. Disk latency is normal, as are temps (29C). System was freshly rebooted as part of disk replacement, and I don't see any concerning messages in dmsg. Is there something I missed or can do to improve resilver times? I know it will take at least a half-day to a day in an optimal environment, but my concern is if the 18MB/s is true and accurate, I'm looking at about a week, which doesn't seem right. I disabled automated Scrub and SMART tests for now so they don't conflict, and my pool is 99% used for reads, infrequent ones at that. It's been idle the 10 hours it's been rebuilding at this performance so far.
To note, there's also no other notable performance issues with the pool. I can consistently move data from it reading at nearly full 10GB line rate with SMB, and writing to the array rests around 300MB/s once RAM-cache runs out. Overall very happy with it, just concerned on my newly discovered resilver times leaving me anxious.
Any advice or input on experience would be appreciated, and thank you in advance! Hoping it magically speeds up overnight while I'm sleeping - else this anxiety caused by rebuild time alone is going to push me to do mirrors next NAS iteration. :D
I'm hoping to get some help on a topic I know comes up frequently, but I'm having trouble understanding how is impacting my setup based on other online results. I had a drive failure today, and I'm in the process of resilvering the drive, but I'm seeing MAX 18MB/s writing to the new drive, and while my resilver percent is moving up for now, the time is only increasing, rather dramatically at that.
System Details:
TrueNAS-13.0-U4
Intel E5-1660 v3, 8C 16T
128GB DDR4 ECC
2x10GB Intel x520-DA2
x2 Toshiba 128GB SATA SSDs for Boot
x16 HUH721010AL42C0 10TB SAS HDDs
(No cache, just spinners)
SuperMicro mobo X10SRH-CF
Supermicro 36 Bay Chassis; SAS-3 backplane, onboard raid card flashed to IT Mode
Pool #1
Encryption on
Sync Standard
no Compression, no DeDup
2 vDevs of 8 drives, each vDev is x8 10TB drives
100TB usable pool size, with 40TB in use and 60TB free
Recent smart tests, long and short, have all passed on all drives (except the bad one I swapped), shorts run daily and longs weekly. The last scrub job was timed poorly and unfortunately timed out due to the bad drive, and hasn't been ran in ~30 days. (plan to run once resilver catches up).
I also noticed I had never set a Resilver priority before this started, so I initially thought that was it. However, even after updating the priority to all-day, the speed hasn't changed and rests at 18MB/s consistently for the last 10 hours. Disk latency is normal, as are temps (29C). System was freshly rebooted as part of disk replacement, and I don't see any concerning messages in dmsg. Is there something I missed or can do to improve resilver times? I know it will take at least a half-day to a day in an optimal environment, but my concern is if the 18MB/s is true and accurate, I'm looking at about a week, which doesn't seem right. I disabled automated Scrub and SMART tests for now so they don't conflict, and my pool is 99% used for reads, infrequent ones at that. It's been idle the 10 hours it's been rebuilding at this performance so far.
To note, there's also no other notable performance issues with the pool. I can consistently move data from it reading at nearly full 10GB line rate with SMB, and writing to the array rests around 300MB/s once RAM-cache runs out. Overall very happy with it, just concerned on my newly discovered resilver times leaving me anxious.
Any advice or input on experience would be appreciated, and thank you in advance! Hoping it magically speeds up overnight while I'm sleeping - else this anxiety caused by rebuild time alone is going to push me to do mirrors next NAS iteration. :D