- Joined
- Apr 24, 2020
- Messages
- 5,399
zpool scrub {PoolName}zpool scrub {PoolName}This... thank you! Let me explain what happenned to me:OK, if you've already deleted the file, try rescrubbing the pool again. If you have snapshots that refer to the deleted file, you should delete those too. Once there are no more references to the corrupt file, scrub your pool again. It may take multiple scrubs before ZFS is happy again.
I forgot to mention I am using TrueNAS Scale 22.12.2, so this is still pretty much valid, most likely for any ZFS system actually.This... thank you! Let me explain what happenned to me:
I sufferred a power loss during a drive replacement (resilvering of the new drive), and consequently got checksum errors on all the 4 drives of my RAIDZ2 pool, relative to only ONE file.
After deleting the file, running "zpool clear pool" and scrubbing the pool, I still got checksum errors relative to the first daily snapshot after the incident happenned.
I deleted the snapshop, cleared the errors and scrubbed, then got more checksum errors related to the next snapshot...
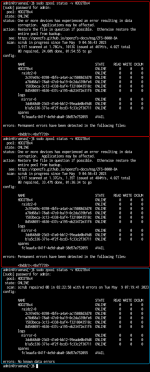
So I gave it some thought and deleted all subsequent snapshots until original problematic file deletion, then performed a "zpool clear pool", and performed another scrub.
I did not understand why, but I still got an error showing, with the pool and filename showing inside brackets, like <pool>:<filename> (meaning the errors relate to a deleted file).
I was becoming a bit desperate and was considering destroying my datasets/pools to recreate them from scratch... fortunately, with a bit of searching, I found this thread explaining that several successive scrubs are necessary to eventually clear the error for good, see screenshot in attachment.
So, thank you all very much for the explanations! I hope this can help someone else facing the same situation!
Regards,
I forgot to mention I am using TrueNAS Scale 22.12.2, so this is still pretty much valid, most likely for any ZFS system actually.
My hardware is my former desktop PC with the following hardware:This sort of error often seems to pop up when you're using a bad disk controller. How are your drives attached to the NAS system? What specific controller? SATA AHCI? LSI HBA? RAID?
I do know this is not ideal bombproof recommended reliable hardware, and I WILL definitely consider a LSI HBA card in IT mode for subsequent needs.
WILL definitely consider a LSI HBA
2 x 256GB mirrorred NVMe drives as Log
Thank you for the advice!Well, even in the realm of suboptimal hardware, there can be better choices and less-good choices. So while I'm not seeing anything obvious that would have led to your pool issues, I do want to comment:
An LSI HBA is probably going to do nothing for you as you seem to have sufficient AHCI ports. AHCI ports can typically run at full speed, while early HBA's such as the LSI 2008 may only run at a fraction (think: maybe 80%) of the speed at least if all ports are busy.
I notice that your board has two M.2 NVMe slots. Also, 256GB is a common consumer SSD size. Since you say these are for "Log", I'm guessing you mean SLOG, and if so, two notes --
1) You don't need to mirror SLOG.
2) A SLOG device really needs power loss protection, or some similar feature such as Optane's cacheless write, or else the SLOG does not serve its intended function correctly. You will just be burning through the endurance on your SSD's.
What I did not know was that LSI HBAs could run slower in certain circumstances.
As many people new to ZFS, I though that "cache" (L2ARC) would speed up read speeds, when in reality it would be counterproductive in most home user scenarios (L2ARC cannot beat RAM speed, and L2ARC does consume a little bit of RAM too).
So I repurposed this SSD to complement the exisiting SLOG SSD, and I made a mirror with both drives. I doubt they have power loss protection. I understand this is not ideal for SLOG. Should I get rid of a dedicated SLOG drive altogether?
Thanks again for your constructive help and advice, and for contributing to the community for such a long time! :)