I am running a fresh and clean install on a R720 with ESXi 6.7U3 and TrueNAS-13.0-U3.1. Using a cross-flashed H710P mini, and H200e. All of the setup went fine and I have it configured enough to do some testing for stability and such. And that is when this issue started happening. I have an R720xd with a very similar setup that has been flawless for years and has been running TruNAS12 for sometime now.
I originally had ESXi and TrueNAS sharing the same management NIC and I would notice overnight that I could no longer access the web interface for either one. Sometimes ESXi would start to load something, but never any response from TrueNAS web interface. A day or two ago I split the management interfaces out to separate network connections and looked over all the ESXi network settings to make sure they matched my stable instance on the R720xd.
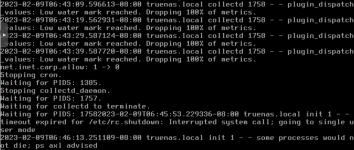
Today the ESXi interface is working properly, but TruNAS web interface will not load. From the ESXi console I seen this message over and over "plugin_dispatch_values: Low water mark reached. Dropping 100% of metrics." I then used WinSCP to try and grab the log files form TrueNAS. I could login through WinSCP, but it would not pull any of the files, WinSCP would just hang there trying to download it.
At this point I started a shutdown on TrueNAS from the ESXi guest shutdown. It struggled with a few things and took some time but then hung hard on the last of this screen shot.

I ended up doing a hard reset and it is back up and running now so I will grab the logs and look through them. Any certain log file I should expect to find the cause in from what is shown above? I do also read about RAM possibly causing this issue, so sounds like a RAM test may be a good idea too.
I originally had ESXi and TrueNAS sharing the same management NIC and I would notice overnight that I could no longer access the web interface for either one. Sometimes ESXi would start to load something, but never any response from TrueNAS web interface. A day or two ago I split the management interfaces out to separate network connections and looked over all the ESXi network settings to make sure they matched my stable instance on the R720xd.
Today the ESXi interface is working properly, but TruNAS web interface will not load. From the ESXi console I seen this message over and over "plugin_dispatch_values: Low water mark reached. Dropping 100% of metrics." I then used WinSCP to try and grab the log files form TrueNAS. I could login through WinSCP, but it would not pull any of the files, WinSCP would just hang there trying to download it.
At this point I started a shutdown on TrueNAS from the ESXi guest shutdown. It struggled with a few things and took some time but then hung hard on the last of this screen shot.
I ended up doing a hard reset and it is back up and running now so I will grab the logs and look through them. Any certain log file I should expect to find the cause in from what is shown above? I do also read about RAM possibly causing this issue, so sounds like a RAM test may be a good idea too.
Last edited: