Hi!
I have a freenas install with some decent hardware for my homelab. I access it using NFSv4 from other hardware for compute. I'm having issues where all of my databases hosted on it over time end up getting locked, and looking at iostat there is an extremely high iowait. Even when I don't have any applications on it, I find that the best performance I can get moving large single files (30 GB) is around 90 MB/s on the NAS itself.
Also, I find that after a few days, the freenas web UI stops being responsive, and SSH starts hanging as well. Even local console hangs after displaying the options menu -- I cannot reboot or drop in a shell. I end up having to clear this by shutting down all of my nfs clients and then hard power cycling the nas.
I have one ZFS pool that contains 4 vdevs, each with a simple 1x1 mirror. There's a 512GB nvme 970 evo being used as a cache and a 480GB Intel Optane SSD 900P being used as a log. I find that the cache and log have a negligible impact on my performance. The vdev drives are 8 TB each, all 7200 rpm NAS or enterprise variety. SMART tests cleanly on all drives.
The base hardware is a HP DL380 G8p with 32 GB of ram. Freenas is installed on an internal SD card (Trascend media rated to 400 MB/s read). I've bypassed the built in HP RAID controller and am using an LSI SAS2308 controller plugged into the built-in HP SAS expander using both ports.
I'm using a SFP+ DAC module, and iperf shows network to not be the bottleneck with 7+ Gbps TCP being thrown in both the send and receive directions.
Here are some stats with compression turned off, log and cache still in place.
Write
Read
Remove the cache d0 and log:
Write
Read
So, single writes and reads on the server itself seem great, but add my real use and things go south. I imagine it's due to having one pool that's covering both DBs and large media. Maybe I got some bad advice and wrongly thought that the log + cache would soften the impact there.
Here's what I'm thinking of doing: move the optane to its own pool, backup to the 970 evo, and shift all of my fragmented + IO heavy use over there. Keep the bigger sequential storage over on the spinning media. Before I go through that effort, is this the "right" layout I should consider? Am I missing a completely separate issue in my setup?
I have a freenas install with some decent hardware for my homelab. I access it using NFSv4 from other hardware for compute. I'm having issues where all of my databases hosted on it over time end up getting locked, and looking at iostat there is an extremely high iowait. Even when I don't have any applications on it, I find that the best performance I can get moving large single files (30 GB) is around 90 MB/s on the NAS itself.
Also, I find that after a few days, the freenas web UI stops being responsive, and SSH starts hanging as well. Even local console hangs after displaying the options menu -- I cannot reboot or drop in a shell. I end up having to clear this by shutting down all of my nfs clients and then hard power cycling the nas.
I have one ZFS pool that contains 4 vdevs, each with a simple 1x1 mirror. There's a 512GB nvme 970 evo being used as a cache and a 480GB Intel Optane SSD 900P being used as a log. I find that the cache and log have a negligible impact on my performance. The vdev drives are 8 TB each, all 7200 rpm NAS or enterprise variety. SMART tests cleanly on all drives.
The base hardware is a HP DL380 G8p with 32 GB of ram. Freenas is installed on an internal SD card (Trascend media rated to 400 MB/s read). I've bypassed the built in HP RAID controller and am using an LSI SAS2308 controller plugged into the built-in HP SAS expander using both ports.
I'm using a SFP+ DAC module, and iperf shows network to not be the bottleneck with 7+ Gbps TCP being thrown in both the send and receive directions.
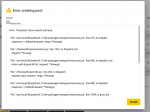
Code:
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
freenas-boot 29.5G 1021M 28.5G - - 0% 3% 1.00x ONLINE -
da8p2 29.5G 1021M 28.5G - - 0% 3%
media 29T 14.2T 14.8T - - 3% 48% 1.00x ONLINE /mnt
mirror 7.25T 3.04T 4.21T - - 4% 41%
gptid/2fa3a238-dcb9-11e9-9b80-2c44fd94cfbc - - - - - - -
gptid/30974b70-dcb9-11e9-9b80-2c44fd94cfbc - - - - - - -
mirror 7.25T 3.06T 4.19T - - 3% 42%
gptid/3194dbe8-dcb9-11e9-9b80-2c44fd94cfbc - - - - - - -
gptid/328c9c6e-dcb9-11e9-9b80-2c44fd94cfbc - - - - - - -
mirror 7.25T 4.59T 2.66T - - 6% 63%
gptid/82e892f9-ebb5-11e9-80ce-2c44fd94cfbc - - - - - - -
gptid/84066d34-ebb5-11e9-80ce-2c44fd94cfbc - - - - - - -
mirror 7.25T 3.50T 3.75T - - 2% 48%
gptid/252f1109-3af5-11ea-a237-2c44fd94cfbc - - - - - - -
gptid/27917278-3af5-11ea-a237-2c44fd94cfbc - - - - - - -
log - - - - - -
gptid/af8851cf-fb7f-11e9-80c0-2c44fd94cfbc 444G 684K 444G - - 0% 0%
cache - - - - - -
gptid/ad393d45-fb7f-11e9-80c0-2c44fd94cfbc 466G 12.6G 453G - - 0% 2%Here are some stats with compression turned off, log and cache still in place.
Write
root@freenas[/mnt/media/test]# dd if=/dev/zero of=/mnt/media/test/blank bs=4M count=10000
10000+0 records in
10000+0 records out
41943040000 bytes transferred in 58.968424 secs (711279650 bytes/sec)
Read
root@freenas[/mnt/media/test]# dd of=/dev/zero if=/mnt/media/test/blank bs=4M count=10000
10000+0 records in
10000+0 records out
41943040000 bytes transferred in 77.398446 secs (541910620 bytes/sec)
Remove the cache d0 and log:
Write
root@freenas[/mnt/media/test]# dd if=/dev/zero of=/mnt/media/test/blank bs=4M count=10000
10000+0 records in
10000+0 records out
41943040000 bytes transferred in 60.318331 secs (695361410 bytes/sec)
Read
root@freenas[/mnt/media/test]# dd of=/dev/zero if=/mnt/media/test/blank bs=4M count=10000
10000+0 records in
10000+0 records out
41943040000 bytes transferred in 81.975561 secs (511652979 bytes/sec)
So, single writes and reads on the server itself seem great, but add my real use and things go south. I imagine it's due to having one pool that's covering both DBs and large media. Maybe I got some bad advice and wrongly thought that the log + cache would soften the impact there.
Here's what I'm thinking of doing: move the optane to its own pool, backup to the 970 evo, and shift all of my fragmented + IO heavy use over there. Keep the bigger sequential storage over on the spinning media. Before I go through that effort, is this the "right" layout I should consider? Am I missing a completely separate issue in my setup?