Hi all,
My setup consists of:
HP DL180 G6
12 Slot LFF Backplane
2x Intel L5520 Xeon 4 Core 2.26Ghz
6x Seagate 7.2K SATA 3TB HDDs
48GB RAM
LSI 9211-8i
configured thusly:
NAME STATE READ WRITE CKSUM
RAID10 ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gptid/de76695d-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
gptid/df1b2423-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/dfc8a9c9-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
gptid/e07bb44e-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
gptid/e12ffb20-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
gptid/e1e8012e-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
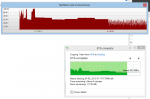
It is serving as an iSCSI target for an ESXi datastore. When I begin transferring large files (in this case, a single 45GB file) to the VM, the graphs look like this:

I have run this test many times and consistently get the same results. I've attempted to do some tuning, but it doesn't seem to make much difference. Can anyone offer some direction as to what might be causing this pattern? I know this setup is capable of sustaining wirespeed (1Gbit) transfers.
My setup consists of:
HP DL180 G6
12 Slot LFF Backplane
2x Intel L5520 Xeon 4 Core 2.26Ghz
6x Seagate 7.2K SATA 3TB HDDs
48GB RAM
LSI 9211-8i
configured thusly:
NAME STATE READ WRITE CKSUM
RAID10 ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gptid/de76695d-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
gptid/df1b2423-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/dfc8a9c9-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
gptid/e07bb44e-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
gptid/e12ffb20-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
gptid/e1e8012e-ec29-11e2-9211-f4ce46bd81ae ONLINE 0 0 0
It is serving as an iSCSI target for an ESXi datastore. When I begin transferring large files (in this case, a single 45GB file) to the VM, the graphs look like this:
I have run this test many times and consistently get the same results. I've attempted to do some tuning, but it doesn't seem to make much difference. Can anyone offer some direction as to what might be causing this pattern? I know this setup is capable of sustaining wirespeed (1Gbit) transfers.