GuillermoX
Cadet
- Joined
- Dec 29, 2020
- Messages
- 7
Hi everyone!
We're in the following scenario, and appreciate your help to advance on the solution of the issue:
Our system description:
HW: FreeNAS Certified 4U24 V2
OS: FreeNAS-9.10.2-U5
24 SAS 8Tb // storage pool
2 SATA DOM SSD 32Gb // mirrored boot
1 SSD 240Gb // L2ARC Read Cache
1 SSD 200Gb // ZIL Write Cache
1) We've received an email alert on Dec 20th with the following information:
2) We've checked on the web GUI and noticed the status of DEGRADED multipath on Storage/View Multipaths, also checked on the console with:
Also on the Alert System on the web GUI:
3) The output of zpool status shows the pool ONLINE but with scrub repaired data:
4) The SMART information output we receive from smart_report.sh script for all disks:
And the output of smartctl -a for the affected device da9:
5) Also, today we've received an email alert with a lof of these messages repeated:
Do you suggest to change the disk? Ww've noticed some uncorrected errors, and other errors corrected on the disk
We've seen on other similar posts in this forum, that suggests to run
Thanks in advance for your comments and support.
Best regards,
We're in the following scenario, and appreciate your help to advance on the solution of the issue:
Our system description:
HW: FreeNAS Certified 4U24 V2
OS: FreeNAS-9.10.2-U5
24 SAS 8Tb // storage pool
2 SATA DOM SSD 32Gb // mirrored boot
1 SSD 240Gb // L2ARC Read Cache
1 SSD 200Gb // ZIL Write Cache
1) We've received an email alert on Dec 20th with the following information:
Code:
freenas.local kernel log messages: > (da33:mpr0:0:62:0): READ(10). CDB: 28 00 04 93 3e a9 00 00 20 00 > (da33:mpr0:0:62:0): CAM status: SCSI Status Error > (da33:mpr0:0:62:0): SCSI status: Check Condition > (da33:mpr0:0:62:0): SCSI sense: MEDIUM ERROR asc:11,0 (Unrecovered read error) > (da33:mpr0:0:62:0): > (da33:mpr0:0:62:0): Field Replaceable Unit: 0 > (da33:mpr0:0:62:0): Command Specific Info: 0 > (da33:mpr0:0:62:0): Actual Retry Count: 123 > (da33:mpr0:0:62:0): Descriptor 0x80: f7 2d > (da33:mpr0:0:62:0): Descriptor 0x81: 00 2f bf 0c 00 a0 > (da33:mpr0:0:62:0): Error 5, Unretryable error > GEOM_MULTIPATH: Error 5, da33 in disk8 marked FAIL > GEOM_MULTIPATH: da9 is now active path in disk8 > (da9:mpr0:0:19:0): READ(10). CDB: 28 00 04 93 3e a9 00 00 20 00 > (da9:mpr0:0:19:0): CAM status: SCSI Status Error > (da9:mpr0:0:19:0): SCSI status: Check Condition > (da9:mpr0:0:19:0): SCSI sense: MEDIUM ERROR asc:11,0 (Unrecovered read error) > (da9:mpr0:0:19:0): > (da9:mpr0:0:19:0): Field Replaceable Unit: 0 > (da9:mpr0:0:19:0): Command Specific Info: 0 > (da9:mpr0:0:19:0): Actual Retry Count: 123 > (da9:mpr0:0:19:0): Descriptor 0x80: f7 2d > (da9:mpr0:0:19:0): Descriptor 0x81: 00 2f bf 0c 00 ad > (da9:mpr0:0:19:0): Error 5, Unretryable error > GEOM_MULTIPATH: Error 5, da9 in disk8 marked FAIL > GEOM_MULTIPATH: all paths in disk8 were marked FAIL, restore da33 > GEOM_MULTIPATH: da33 is now active path in disk8 > (da33:mpr0:0:62:0): READ(10). CDB: 28 00 17 c1 a0 b9 00 00 01 00 > (da33:mpr0:0:62:0): CAM status: SCSI Status Error > (da33:mpr0:0:62:0): SCSI status: Check Condition > (da33:mpr0:0:62:0): SCSI sense: MEDIUM ERROR asc:11,0 (Unrecovered read error) > (da33:mpr0:0:62:0): > (da33:mpr0:0:62:0): Field Replaceable Unit: 0 > (da33:mpr0:0:62:0): Command Specific Info: 0 > (da33:mpr0:0:62:0): Actual Retry Count: 123 > (da33:mpr0:0:62:0): Descriptor 0x80: f7 1f > (da33:mpr0:0:62:0): Descriptor 0x81: 01 01 68 0c 00 99 > (da33:mpr0:0:62:0): Error 5, Unretryable error > GEOM_MULTIPATH: Error 5, da33 in disk8 marked FAIL > GEOM_MULTIPATH: all paths in disk8 were marked FAIL, restore da9 > GEOM_MULTIPATH: da9 is now active path in disk8 -- End of security output --
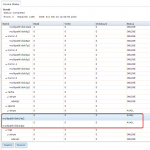
2) We've checked on the web GUI and noticed the status of DEGRADED multipath on Storage/View Multipaths, also checked on the console with:
Code:
# gmultipath status -s ... multipath/disk1 OPTIMAL da34 (ACTIVE) multipath/disk1 OPTIMAL da10 (PASSIVE) multipath/disk8 DEGRADED da33 (FAIL) multipath/disk8 DEGRADED da9 (ACTIVE) multipath/disk16 OPTIMAL da32 (ACTIVE) multipath/disk16 OPTIMAL da8 (PASSIVE) ... (resumed output)
Also on the Alert System on the web GUI:
CRITICAL: Dec. 20, 2020, 12:24 a.m. - The following multipaths are not optimal: disk83) The output of zpool status shows the pool ONLINE but with scrub repaired data:
Code:
# zpool status
pool: datos
state: ONLINE
scan: scrub repaired 128K in 12h50m with 0 errors on Sun Dec 20 12:50:56 2020
config:
NAME STATE READ WRITE CKSUM
datos ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gptid/4267f34f-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/42eabbff-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/4351b1c6-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/43b65fc5-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-2 ONLINE 0 0 0
gptid/44297dae-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/44915638-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-3 ONLINE 0 0 0
gptid/45078510-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/4576239b-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-4 ONLINE 0 0 0
gptid/45e345bc-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/46512b37-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-5 ONLINE 0 0 0
gptid/46c03cba-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/4728a4ee-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-6 ONLINE 0 0 0
gptid/4799e412-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/5afa7c7a-47c0-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-7 ONLINE 0 0 0
gptid/bf445c67-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/bfb100c9-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-8 ONLINE 0 0 0
gptid/c643dd7f-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/c6afeca0-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-9 ONLINE 0 0 0
gptid/cd711e67-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/cdda6714-47bf-11e7-af51-0007433c9d20 ONLINE 0 0 0
mirror-10 ONLINE 0 0 0
gptid/2066e757-47c0-11e7-af51-0007433c9d20 ONLINE 0 0 0
gptid/20d14e0e-47c0-11e7-af51-0007433c9d20 ONLINE 0 0 0
logs
gptid/edcb224a-47c0-11e7-af51-0007433c9d20 ONLINE 0 0 0
cache
gptid/db611e37-47c0-11e7-af51-0007433c9d20 ONLINE 0 0 0
spares
gptid/b8eafac2-4a16-11e7-b7f6-0007433c9d20 AVAIL
gptid/3129c309-9728-11e7-b00d-0007433c9d20 AVAIL
errors: No known data errors
pool: freenas-boot
state: ONLINE
scan: scrub repaired 0 in 0h0m with 0 errors on Tue Dec 22 03:45:10 2020
config:
NAME STATE READ WRITE CKSUM
freenas-boot ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada3p2 ONLINE 0 0 0
ada2p2 ONLINE 0 0 0
errors: No known data errors4) The SMART information output we receive from smart_report.sh script for all disks:
Code:
########## SMART status report summary for all SAS drives on server FREENAS ########## +------+------------------------+----+-----+------+------+------+------+------+------+ |Device|Serial |Temp|Start|Load |Defect|Uncorr|Uncorr|Uncorr|Non | | |Number | |Stop |Unload|List |Read |Write |Verify|Medium| | | | |Count|Count |Elems |Errors|Errors|Errors|Errors| +------+------------------------+----+-----+------+------+------+------+------+------+ |da0 |VLH85Z3V | 37| 53| 1415| 0| 0| 0| 0| 0| |da1 |VLJ5PDEV | 36| 53| 1413| 0| 0| 0| 0| 0| |da2 |VLH6TE1V | 37| 52| 1413| 0| 0| 0| 0| 0| |da3 |VLHE11MV | 35| 53| 1415| 0| 0| 0| 0| 0| |da4 |VLH96KWV | 35| 53|294160| 0| 0| 42| 0| 0| |da5 |VLHE40LV | 32| 53| 1417| 0| 0| 0| 0| 0| |da6 |VLHE3HRV | 38| 53| 1818| 0| 0| 0| 0| 0| |da7 |VLJ4Y0AV | 39| 53| 1416| 0| 0| 0| 0| 0| |da8 |VLJ3WBMV | 40| 53| 1421| 0| 0| 0| 0| 0| |da9 |VLHE11RV | 38| 53| 1419| 2| 5| 0| 0| 0| |da10 |VLHE5MWV | 37| 53| 1609| 0| 0| 0| 0| 0| |da11 |VLGSGP4V | 32| 52| 1415| 0| 0| 0| 0| 0| |da12 |VLHE12WV | 39| 53| 1414| 0| 0| 0| 0| 0| |da13 |VLHA85NV | 40| 52| 1503| 0| 0| 0| 0| 0| |da14 |VLHJDRPV | 40| 52| 1416| 0| 0| 0| 0| 0| |da15 |VLHJDH8V | 39| 52| 1415| 0| 0| 0| 0| 0| |da16 |VLJ5PJ8V | 36| 52| 1419| 0| 0| 0| 0| 0| |da17 |VLH14ZEV | 33| 53| 1414| 0| 0| 0| 0| 0| |da18 |VLHE0VKV | 38| 52| 1543| 0| 0| 0| 0| 0| |da19 |VLH977VV | 39| 53| 1415| 0| 0| 0| 0| 0| |da20 |VLH961TV | 39| 21| 56| 0| 0| 0| 0| 0| |da21 |VLH7U1KV | 38| 53| 1417| 0| 0| 0| 0| 0| |da22 |VLHJDP4V | 36| 52| 1414| 0| 0| 0| 0| 0| |da23 |VLH9E7EV | 34| 53| 663| 0| 0| 0| 0| 0|
And the output of smartctl -a for the affected device da9:
Code:
# smartctl -a /dev/da9
smartctl 6.5 2016-05-07 r4318 [FreeBSD 10.3-STABLE amd64] (local build)
Copyright (C) 2002-16, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Vendor: HGST
Product: HUH728080AL4200
Revision: A907
Compliance: SPC-4
User Capacity: 8,001,563,222,016 bytes [8.00 TB]
Logical block size: 4096 bytes
LU is fully provisioned
Rotation Rate: 7200 rpm
Form Factor: 3.5 inches
Logical Unit id: 0x5000cca260501128
Serial number: VLHE11RV
Device type: disk
Transport protocol: SAS (SPL-3)
Local Time is: Tue Dec 29 11:50:33 2020 ART
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Temperature Warning: Enabled
=== START OF READ SMART DATA SECTION ===
SMART Health Status: OK
Current Drive Temperature: 38 C
Drive Trip Temperature: 85 C
Manufactured in week 36 of year 2016
Specified cycle count over device lifetime: 50000
Accumulated start-stop cycles: 53
Specified load-unload count over device lifetime: 600000
Accumulated load-unload cycles: 1419
Elements in grown defect list: 2
Vendor (Seagate) cache information
Blocks sent to initiator = 4439804951396352
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 1463 0 1463 1113501 124796.107 5
write: 0 2 0 2 500375 16175.706 0
verify: 0 0 0 0 2640440 0.000 0
Non-medium error count: 05) Also, today we've received an email alert with a lof of these messages repeated:
Code:
freenas.local kernel log messages: > mpr0: mpr_user_pass_thru: user reply buffer (64) smaller than returned buffer (68) > mpr1: mpr_user_pass_thru: user reply buffer (64) smaller than returned buffer (68) > mpr0: mpr_user_pass_thru: user reply buffer (48) smaller than returned buffer (52) > mpr0: mpr_user_pass_thru: user reply buffer (48) smaller than returned buffer (52)
Do you suggest to change the disk? Ww've noticed some uncorrected errors, and other errors corrected on the disk
We've seen on other similar posts in this forum, that suggests to run
gmultipath restore to clear the FAIL status. It's OK to run that command and see how it evolves? Thanks in advance for your comments and support.
Best regards,