I am currently in the process of moving our FreeNAS boxes from experimental-ish production to 5 year, solid, don't-touch-them-again production. With this goal in mind I'm trying to do some math to ensure that what I build can handle the IOPS load in the long run. Right now I'm just running single, big RaidZ2 sets on each array. Here is how I'm going about the calculations:
I am using WD RED disks. These aren't very fast, but originally these boxes were just supposed to hold video recordings for a year or two from the surveillance system, so we're pretty much stuck with those at this point.
Basically, according to this link http://www.ryanfrantz.com/posts/calculating-disk-iops/ we can calculate IOPS for a single disk like this: IOPS = 1/(avgLatency + AvgSeek). For a WD Red 3TB, that = 30.4136253.
This review http://www.storagereview.com/western_digital_red_nas_hard_drive_review_wd30efrx puts the WD30EFRX at 45 IOPS read and 112 IOPS write. According to some performance analytics I've been running on these applications and arrays with Dell DPACK2, perfmon and nmon, my read/write load balance is 71% reads /29% writes.
It is also commonly stated that a RAIDZ volume's write performance is only as good as a single disk's IOPS, so if I am going to use RAIDZ, it's important to understand how much that really is.
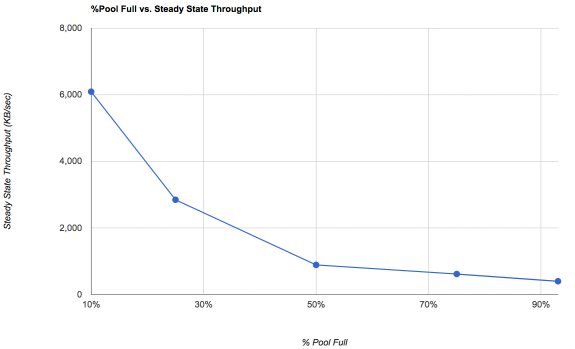
I've also been monitoring the read and write IOPS on the arrays and applications and I keep coming up with very similar numbers over 4 day 1 second sample times. I am seeing way more IOPS than either of these arrays should be able to do according to the rule of RAIDZ volume's write performance is only as good as a single disk's IOPS. I am doing super random writes that can't possibly be all being cached. MY ARC hit ratio is about 99& but my L2ARC SSDs are only hitting 14-25%, so I don't think that is it.
My question is, if that rule is true, how am I seeing 800+ IOPS at 95% occur on these arrays that should be limited to 30IOPS of writes? By my math, if I have a ~30% write load and 800 IOPS, that is 240 write IOPS occurring at my 95th percentile.
I am using WD RED disks. These aren't very fast, but originally these boxes were just supposed to hold video recordings for a year or two from the surveillance system, so we're pretty much stuck with those at this point.
Basically, according to this link http://www.ryanfrantz.com/posts/calculating-disk-iops/ we can calculate IOPS for a single disk like this: IOPS = 1/(avgLatency + AvgSeek). For a WD Red 3TB, that = 30.4136253.
This review http://www.storagereview.com/western_digital_red_nas_hard_drive_review_wd30efrx puts the WD30EFRX at 45 IOPS read and 112 IOPS write. According to some performance analytics I've been running on these applications and arrays with Dell DPACK2, perfmon and nmon, my read/write load balance is 71% reads /29% writes.
It is also commonly stated that a RAIDZ volume's write performance is only as good as a single disk's IOPS, so if I am going to use RAIDZ, it's important to understand how much that really is.
I've also been monitoring the read and write IOPS on the arrays and applications and I keep coming up with very similar numbers over 4 day 1 second sample times. I am seeing way more IOPS than either of these arrays should be able to do according to the rule of RAIDZ volume's write performance is only as good as a single disk's IOPS. I am doing super random writes that can't possibly be all being cached. MY ARC hit ratio is about 99& but my L2ARC SSDs are only hitting 14-25%, so I don't think that is it.
My question is, if that rule is true, how am I seeing 800+ IOPS at 95% occur on these arrays that should be limited to 30IOPS of writes? By my math, if I have a ~30% write load and 800 IOPS, that is 240 write IOPS occurring at my 95th percentile.