Jarrodspencerharper
Cadet
- Joined
- Oct 16, 2016
- Messages
- 6
I have a HP N40L , 8gb ram running freenas 8.3 with two 2tb drives running as a zfs mirror. I set this up about 5 years ago and have never had any issues. I use it for personal use at home to store photos, movies, music etc.
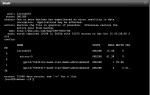
I noticed the other day i got an alert saying some corruption was detected so i ran a zpool status -v and i got the output in the attachment.
My question is has one of my drives failed? If so how would i know which one?
Thanks in advance.
I noticed the other day i got an alert saying some corruption was detected so i ran a zpool status -v and i got the output in the attachment.
My question is has one of my drives failed? If so how would i know which one?
Thanks in advance.