I have 5 VM's running on a 32core AMD Threadripper 2990wx with 128 GB of ram.
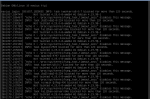
Randomly it seems these servers are going down where you can't access them via SSH and when you use the VNC built into FreeNAS, I see the errors in the attached screenshot.
It seems the only way to fix the problem (temporarily) is to reboot the server, till it happens again.
Not sure where to look on this matter.
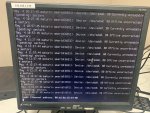
Randomly it seems these servers are going down where you can't access them via SSH and when you use the VNC built into FreeNAS, I see the errors in the attached screenshot.
It seems the only way to fix the problem (temporarily) is to reboot the server, till it happens again.
Not sure where to look on this matter.