Warren Ince
Cadet
- Joined
- Jul 18, 2023
- Messages
- 1
Hiya,
I have a failed disk that I'm trying to offline (following below link) before replacing but nothing happens when we "Select Confirm to activate the OFFLINE button, then click OFFLINE. The disk should now be offline"

 www.truenas.com
www.truenas.com
Version: TrueNAS-12.0-U3
Supermicro (Family SMC X10)
Product Name: X10DRH-iT
2 x Intel(R) Xeon(R) CPU E5-2609 v3 @ 1.90GHz
Has anyone else experienced this? Zpool status below.
root@LON-ESXi-NAS-02[~]# zpool status
pool: SAS-3-Mirror-SLOG-Cache
state: DEGRADED
status: One or more devices are faulted in response to persistent errors.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Replace the faulted device, or use 'zpool clear' to mark the device
repaired.
scan: scrub repaired 0B in 08:09:18 with 0 errors on Sun Jul 2 08:09:26 2023
config:
NAME STATE READ WRITE CKSUM
SAS-3-Mirror-SLOG-Cache DEGRADED 0 0 0
mirror-0 ONLINE 0 0 0
gptid/3e17d4f3-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/3f834ec0-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/34d2add4-e3fd-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/3eb510eb-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/41136a76-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/414b449f-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-2 DEGRADED 0 0 0
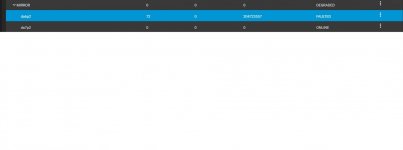
gptid/402f7a69-9df6-11eb-af7d-3cfdfebaf4f0 FAULTED 72 0 72.0M too many errors
gptid/431a58ec-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/435cb0bd-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-3 ONLINE 0 0 0
gptid/41876105-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/44776db4-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/44c4412d-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-4 ONLINE 0 0 0
gptid/4397a148-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/45d7cbf9-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4738a27d-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-5 ONLINE 0 0 0
gptid/46bb93b2-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/488689ed-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4968a4b5-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-6 ONLINE 0 0 0
gptid/4aa8b5fa-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4b6d8656-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4baf8a36-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-7 ONLINE 0 0 0
gptid/4c49a23a-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4c2f09be-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4c9b3374-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
logs
mirror-8 ONLINE 0 0 0
gptid/4b6a05ba-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
cache
gptid/4bf21e06-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
errors: No known data errors
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:03 with 0 errors on Sun Jul 16 03:45:04 2023
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
ada0p2 ONLINE 0 0 0
errors: No known data errors
root@LON-ESXi-NAS-02[~]#
I have a failed disk that I'm trying to offline (following below link) before replacing but nothing happens when we "Select Confirm to activate the OFFLINE button, then click OFFLINE. The disk should now be offline"
Disk Replacement
Describes how to replace a disk and restore the hot spare in TrueNAS CORE.
Version: TrueNAS-12.0-U3
Supermicro (Family SMC X10)
Product Name: X10DRH-iT
2 x Intel(R) Xeon(R) CPU E5-2609 v3 @ 1.90GHz
Has anyone else experienced this? Zpool status below.
root@LON-ESXi-NAS-02[~]# zpool status
pool: SAS-3-Mirror-SLOG-Cache
state: DEGRADED
status: One or more devices are faulted in response to persistent errors.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Replace the faulted device, or use 'zpool clear' to mark the device
repaired.
scan: scrub repaired 0B in 08:09:18 with 0 errors on Sun Jul 2 08:09:26 2023
config:
NAME STATE READ WRITE CKSUM
SAS-3-Mirror-SLOG-Cache DEGRADED 0 0 0
mirror-0 ONLINE 0 0 0
gptid/3e17d4f3-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/3f834ec0-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/34d2add4-e3fd-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/3eb510eb-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/41136a76-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/414b449f-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-2 DEGRADED 0 0 0
gptid/402f7a69-9df6-11eb-af7d-3cfdfebaf4f0 FAULTED 72 0 72.0M too many errors
gptid/431a58ec-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/435cb0bd-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-3 ONLINE 0 0 0
gptid/41876105-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/44776db4-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/44c4412d-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-4 ONLINE 0 0 0
gptid/4397a148-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/45d7cbf9-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4738a27d-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-5 ONLINE 0 0 0
gptid/46bb93b2-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/488689ed-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4968a4b5-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-6 ONLINE 0 0 0
gptid/4aa8b5fa-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4b6d8656-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4baf8a36-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
mirror-7 ONLINE 0 0 0
gptid/4c49a23a-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4c2f09be-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
gptid/4c9b3374-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
logs
mirror-8 ONLINE 0 0 0
gptid/4b6a05ba-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
cache
gptid/4bf21e06-9df6-11eb-af7d-3cfdfebaf4f0 ONLINE 0 0 0
errors: No known data errors
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:03 with 0 errors on Sun Jul 16 03:45:04 2023
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
ada0p2 ONLINE 0 0 0
errors: No known data errors
root@LON-ESXi-NAS-02[~]#