deadlock
Cadet
- Joined
- Oct 2, 2011
- Messages
- 5
Hi all,
I just switched from FreeNAS 7 to FreeNAS 8. That also implied a switch from softraid5 to zfs.
At the same time I bought a new serve from SuperMicro.
My server is a Intel core i7 (4 cores) 2533 Mhz
I have 16GB (4x4) of ECC memory (Kingston 65525-008.A00LF)
I have 4x SEAGATE BARRACUDA GREEN 2TB 5900RPM SATA/600 64MB which together form a RAIDZ pool.
dmesg is attached to this message for details
Now to the problem!
The first few hours the pool worked perfectly. I set up offsite replication via zfs send & zfs receive. Storing around 1.5 TB of data sharing it over CIFS, AFP, NFS. Booting some VMWare Virtual machines over NFS. Everything working great!
OK, NFS write times were a bit slow and VMWare sometimes did get timeouts over NFS (I know I should put the ZIL on a separate SSD disk to speed it up since VMWare does atomic writes, so this is solvable)
However from dmesg I could see that I also was starting to get timeouts on disk #4. Ex:
ahcich3: Timeout on slot 30 port 0
ahcich3: is 00000000 cs 40000000 ss 00000000 rs 40000000 tfd c0 serr 00000000
ahcich3: AHCI reset: device not ready after 31000ms (tfd = 00000080)
ahcich3: Timeout on slot 30 port 0
ahcich3: is 00000000 cs 40000000 ss 00000000 rs 40000000 tfd 80 serr 00000000
ahcich3: AHCI reset: device not ready after 31000ms (tfd = 00000080)
ahcich3: Timeout on slot 30 port 0
ahcich3: is 00000000 cs 40000000 ss 00000000 rs 40000000 tfd 80 serr 00000000
Soon after that I lost disk #4
(ada3:ahcich3:0:0:0): lost device
I rebooted the system but the drive didn't even show up in BIOS. After I shut down the system (pulling the powerplug) and restarted, the disk would once again reconnect.
Running zpool status I could see that I had some checksum errors now and with -v I realized that I lost some files. How can this be?? Shouldn't it be redundant. One disk failed but I still had 3 disks left that should contain the correct data?
Anyway, I put the failing disk in a USB cradle and executed SeaTools on it. No errors were reported. I runned the bad sector scan in SeaTools once again. No errors! (about 16 hours runtime)
I bought a replacement disk anyway just to be safe. I put it in the server today and issued a zfs replace. It did rebuild most of the disk overnight. This morning it was stuck at 100%. I guess that there were some finishing up after it reached 100%...
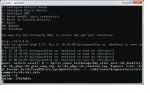
An hour later. KERNEL PANIC! :/
(See attached screenshot zfs panic 2011-10-12.png)
I rebooted the server and once again after 5 minutes of runtime I get another kernel panic (same text). I am now suspecting that the meta-data in the zfs pool have been corrupted.
I have now rebooted the server once again and have now booted memtest86 and checking the memory in ECC mode. ECC memory should never have any problems, right? so I dont know if this will do any good. (mentest86 is in progress as I write)
I am out of ideas now. Completely stuck. Can anyone suggest anything for me to investigate further?
Kind regards
Jens
I just switched from FreeNAS 7 to FreeNAS 8. That also implied a switch from softraid5 to zfs.
At the same time I bought a new serve from SuperMicro.
My server is a Intel core i7 (4 cores) 2533 Mhz
I have 16GB (4x4) of ECC memory (Kingston 65525-008.A00LF)
I have 4x SEAGATE BARRACUDA GREEN 2TB 5900RPM SATA/600 64MB which together form a RAIDZ pool.
dmesg is attached to this message for details
Now to the problem!
The first few hours the pool worked perfectly. I set up offsite replication via zfs send & zfs receive. Storing around 1.5 TB of data sharing it over CIFS, AFP, NFS. Booting some VMWare Virtual machines over NFS. Everything working great!
OK, NFS write times were a bit slow and VMWare sometimes did get timeouts over NFS (I know I should put the ZIL on a separate SSD disk to speed it up since VMWare does atomic writes, so this is solvable)
However from dmesg I could see that I also was starting to get timeouts on disk #4. Ex:
ahcich3: Timeout on slot 30 port 0
ahcich3: is 00000000 cs 40000000 ss 00000000 rs 40000000 tfd c0 serr 00000000
ahcich3: AHCI reset: device not ready after 31000ms (tfd = 00000080)
ahcich3: Timeout on slot 30 port 0
ahcich3: is 00000000 cs 40000000 ss 00000000 rs 40000000 tfd 80 serr 00000000
ahcich3: AHCI reset: device not ready after 31000ms (tfd = 00000080)
ahcich3: Timeout on slot 30 port 0
ahcich3: is 00000000 cs 40000000 ss 00000000 rs 40000000 tfd 80 serr 00000000
Soon after that I lost disk #4
(ada3:ahcich3:0:0:0): lost device
I rebooted the system but the drive didn't even show up in BIOS. After I shut down the system (pulling the powerplug) and restarted, the disk would once again reconnect.
Running zpool status I could see that I had some checksum errors now and with -v I realized that I lost some files. How can this be?? Shouldn't it be redundant. One disk failed but I still had 3 disks left that should contain the correct data?
Anyway, I put the failing disk in a USB cradle and executed SeaTools on it. No errors were reported. I runned the bad sector scan in SeaTools once again. No errors! (about 16 hours runtime)
I bought a replacement disk anyway just to be safe. I put it in the server today and issued a zfs replace. It did rebuild most of the disk overnight. This morning it was stuck at 100%. I guess that there were some finishing up after it reached 100%...
An hour later. KERNEL PANIC! :/
(See attached screenshot zfs panic 2011-10-12.png)
I rebooted the server and once again after 5 minutes of runtime I get another kernel panic (same text). I am now suspecting that the meta-data in the zfs pool have been corrupted.
I have now rebooted the server once again and have now booted memtest86 and checking the memory in ECC mode. ECC memory should never have any problems, right? so I dont know if this will do any good. (mentest86 is in progress as I write)
I am out of ideas now. Completely stuck. Can anyone suggest anything for me to investigate further?
Kind regards
Jens