Squigley
Dabbler
- Joined
- May 13, 2020
- Messages
- 19
I have also opened this in Jira: https://jira.ixsystems.com/browse/NAS-108783
I am posting in here in case anyone has the same problem and checks in here rather than in Jira.
System was running fine. After a few days I found it to be unreachable.
Console showed it hung just after listing the drives and USB ports.
A force reset appeared to boot up properly, but after it imports the disks/pool, it has a kernel crash and reboots itself, every time.
It looks similar to NAS-108257 and NAS-107953, but I don't have an encrypted pool, and I thought maybe the issue was caused by a bunch of client NFS machines trying to access it, and all attacking it as soon as it becomes available again, causing it to immediately crash, but unplugging the network cables makes no difference.
If I unplug all the disks of the pool, then it boots up fine.
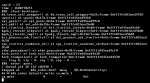
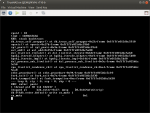
The crash message every time is attached.
For searching purposes (I used OCR from a screenshot rather than type this out manually.. I think it's correct) it includes:
Hardware is a Dell R710, with 128GB RAM (memtested fine), 2x X5670 CPUs, Ubuntu 20.04 is installed on the metal, using KVM to boot a VM, with raw access to partitions on an SSD to boot from, and it has PCI passthrough for 2 NICs (which are an LACP bond), and an LSI HBA controller with 5x 3TB disks attached.
It was working fine, for the past few weeks, and now it's just stuck in this boot loop.
The only thing I changed recently was to set the pool to have sync disabled, as the disk performance was abysmal (2MB/sec writes when trying to copy ISOs etc). (Edit: Maybe sync=disabled is a bad idea.. however the server is on a UPS, and I gave it an SSD 1.2GB SLOG device in front of the 3TB rust drives, so figured that was fairly safe..)
I tried booting up a different VM, but using the same disks, and the result was the same.
I am posting in here in case anyone has the same problem and checks in here rather than in Jira.
System was running fine. After a few days I found it to be unreachable.
Console showed it hung just after listing the drives and USB ports.
A force reset appeared to boot up properly, but after it imports the disks/pool, it has a kernel crash and reboots itself, every time.
It looks similar to NAS-108257 and NAS-107953, but I don't have an encrypted pool, and I thought maybe the issue was caused by a bunch of client NFS machines trying to access it, and all attacking it as soon as it becomes available again, causing it to immediately crash, but unplugging the network cables makes no difference.
If I unplug all the disks of the pool, then it boots up fine.
The crash message every time is attached.
For searching purposes (I used OCR from a screenshot rather than type this out manually.. I think it's correct) it includes:
Code:
KDB: stack backtrace: db_trace_self_wrapper() at db_trace self wrapper.0x2b/frame Oxfffffe015d6c5910 vpanic() at vpanic.0x17b/frame Oxfffffe015d6c5960 spl_panic() at spl_panic.0x3a/frame Oxfffffe015d6c59c0 avl_add() at avl_add.0x156/frame Oxfffffe015d6c5a00 dsl_livelist_iterate() at dsl_livelist iterate.OxbO/frame Oxfffffe015d6c5a60 bpobj_iterate_blkptrs() at bpobj_iterate_blkptrs.Oxff/frame Oxfffffe015d6c5b00 bpobj_iterate_impl() at bpobj_iterate_imp1.0x14d/frame Oxfffffe015d6c5bd0 dsl_process_sub_livelist() at dsl_process_sub_livelist.0x5c/frame Oxfffffe015d6c spa_livelist_condense_cb() at spa_livelist_condense_cb.Oxal/frame Oxfffffe015d6c zthr_procedure() at zthr_procedure.0x94/frame Oxfffffe015d6c5cf0 fork_exit() at fork exit.0x7e/frame Oxfffffe015d6c5d30 fork trampoline() at fork_trampoline.Oxe/frame Oxfffffe015d6c5d30 — trap 0 rip = 0 rsp = 0, rbp = 0 — KDB: enter: panic [ thread pid 38 tid 102647 ] Stopped at kdb_enter.0x37: movg $0,0x164afc6(%rip) db:0:kdb.enter.default> write cn_mute cn_mute 0 0x1
Hardware is a Dell R710, with 128GB RAM (memtested fine), 2x X5670 CPUs, Ubuntu 20.04 is installed on the metal, using KVM to boot a VM, with raw access to partitions on an SSD to boot from, and it has PCI passthrough for 2 NICs (which are an LACP bond), and an LSI HBA controller with 5x 3TB disks attached.
It was working fine, for the past few weeks, and now it's just stuck in this boot loop.
The only thing I changed recently was to set the pool to have sync disabled, as the disk performance was abysmal (2MB/sec writes when trying to copy ISOs etc). (Edit: Maybe sync=disabled is a bad idea.. however the server is on a UPS, and I gave it an SSD 1.2GB SLOG device in front of the 3TB rust drives, so figured that was fairly safe..)
I tried booting up a different VM, but using the same disks, and the result was the same.
Attachments
Last edited: